

One of the questions we get asked by customers a lot is “Can your bot learn on its own?”. The popular belief is that a bot is truly intelligent only when it is able to learn on its own. Here, we will examine what the aforementioned question really means, and what our approach to teaching bots is at Haptik.
Before we get started on self-learning bots, let us first understand how bots are built. There are broadly two major approaches to building chatbots.
Approaches to Chatbot Development
1. Retrieval Based
Retrieval based bots work on the principle of directed flows or graphs. The bot is trained to rank the best response from a finite set of predefined responses. The responses here are entered manually, or based on a knowledge base of pre-existing information.
Eg. What are your store timings?
Answer: 9 to 5 pm
These systems can be extended to integrate with 3rd Party systems as well.
Eg. Where is my order?
Answer: It’s on its way and should reach you in 10 mins
Retrieval based bots are the most common types of chatbots that you see today. They allow bot developers and UX to control the experience and match it to the expectations of our customers. They work best for goal-oriented bots in customer support, lead generation and feedback. We can decide the tone of the bot, and design the experience, keeping in mind the customer’s brand and reputation.
2. Generative
Another method of building chatbots is using a generative model. We based our generative models on the seq2seq neural network. This network was initially released for machine translation, but has also proved to be quite effective when it comes to building generative chatbots. These chatbots are not built with predefined responses. Instead, they are trained using a large number of previous conversations, based upon which responses to the user are generated. We won’t delve too deeply into how generative models work. You can learn more about generative models.
Generative models are good for conversational chatbots with whom the user is simply looking to exchange banter. These models will virtually always have a response ready for you. However, in many cases, the responses might be arbitrary and not make a lot of sense to you. The chatbot is also prone to generating answers with incorrect grammar and syntax.
Generative chatbots also require a very large amount of conversational data to train. We trained our seq2seq implementation for our reminders bot using 2 million conversations. Customers usually do not always have this large amount of data readily available.
LEARN MORE: Live Chat Agent: Bringing a Human Touch to Conversational AI
Generative + Retrieval
It’s important to apply technology in the appropriate context to make sure we are delivering value to our customers as well as to the end users. Our approach at Haptik has been to employ a mixed model that takes the best of both worlds.
The Generative model primarily helps us improve small talk capabilities i.e. Chit chat and banter that our users might want to indulge in with the bot. You can select and customize the tone of small talk – Funny, Formal etc.
However, the primary focus of our bots is to keep in mind the goal of the customer, to help users resolve support queries, and to provide them with information. A retrieval based system is best equipped to meet such needs today.
A research paper by our machine learning team dives deeper into the implementation of such a model.
Self Learning
So how do we build a self-learning bot for retrieval based systems and generative systems?
Generative systems require simply feeding in the response to a particular question that may be missing from the initial training set. To make the bot self-learning, bot developers have taken an approach to let users themselves train the bot. This has had a lot of unexpected consequences.
The Microsoft Tay Bot, for example, was gamed by users using the ‘repeat after me’ function. This function was built to let users on Twitter train the bot and let it learn by itself. However, without any filter on what the bot was being trained on, it didn’t take long for users with mal-intent to retrain the bot with hate speech and extreme right-wing propaganda.
Thus, it is evident that Self-learning generative models can be quite risky, given the potential for bots to be reprogrammed by users.
Training retrieval based systems required to keep the bot learning on its own involves a few categories of self-learning:
1. New Intents
Users are showing a new intent. The bot might have been built only for ordering a pizza, but not for cancellation of the order. This requires a bot developer to build the order cancellation intent and integrate with the Cancellation API.
Haptik’s system semi-automates this process. The system automatically aggregates and recommend new intents based on user conversations. A human agent can then choose to add it to the bot’s knowledge base or reject it.
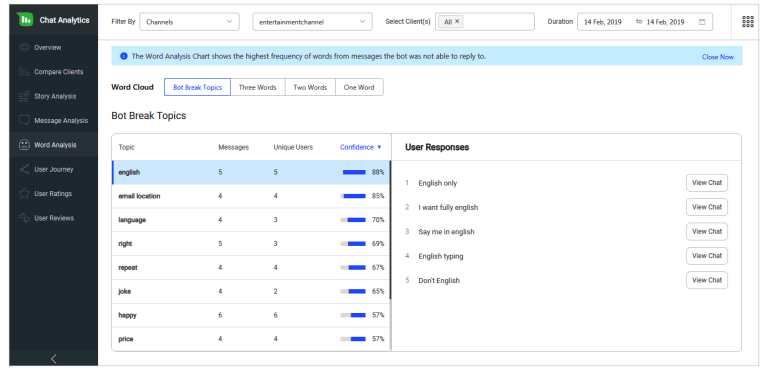
2. Missing Variations
The other category is missing data. The system reflects this as well, by recommending new variations for a particular intent that is similar to the existing intents. However to prevent bad/garbage data from polluting the bot’s intelligence, this also needs to be cleared by a human agent. The agent will evaluate the data and test the bot, to make sure that no existing functionality has been affected.
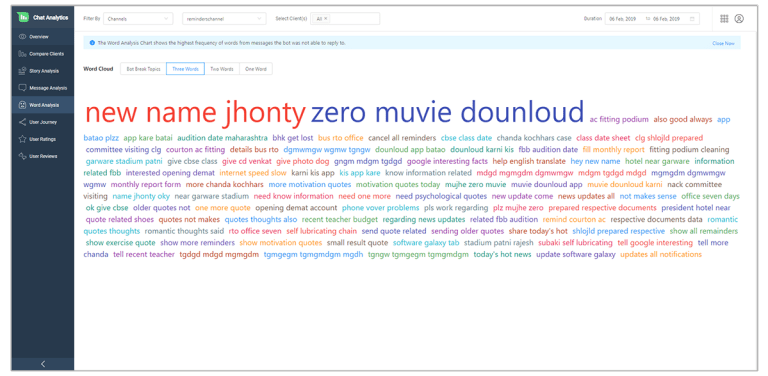
3. Incorrectly Labelled Variations
This is the hardest category to solve for since in this case the bot has managed to respond to the user, but it is an incorrect response. We focus on keeping a close eye on User Feedback, with our built in CSAT system for every chat. Users can mark a particular conversation as helpful or not helpful. Our Bot QA then reviews these conversations to check if the bot needs tuning.
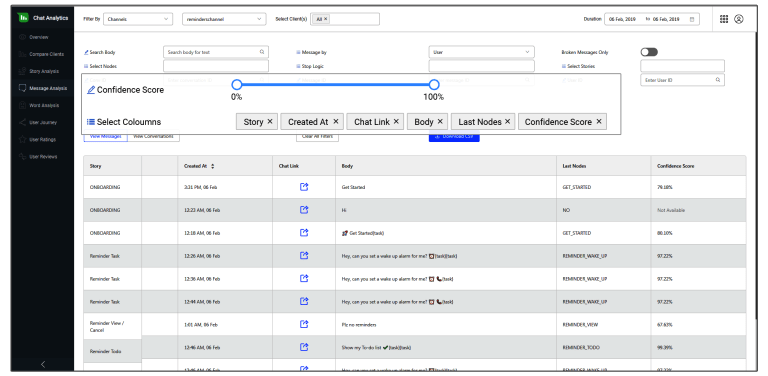
4. Contextual Word Representations
This is an ongoing process to improve the word embeddings used by the bot. These embeddings provide and expand the vocabulary of the bot. By adding more data about how users from different geographies use colloquial language, the bot gains a better understanding of these nuances. Haptik is fortunate to have hundreds of millions of past conversational messages to learn from. New conversational data with new vocabulary is regularly used to retrain the word embedding models on a regular basis. This allows bot A to get smarter with data from bot B!
Read what our Co-founder & CTO- Swapan Rajdev has to say about How Chatbot Breaks, and How to Handle
Conclusion
We might see self-learning chatbots like Iron Man’s JARVIS in the coming decade, but they’re not quite production ready solutions for businesses today.
The approach on how chatbot learns discussed above is known as Human-In-The-Loop(HITL) learning. HITL leverages both human and machine intelligence to create machine learning models. People are constantly involved in the training, tuning and testing of these bots. Haptik’s system is meant to empower these individuals, by giving them the tools to do their job better. Our unique conversational analytics tool is built for that very purpose.
Our Active Learning system prompts our bot trainers to verify messages that have a low confidence score and validate those judgements before feeding them back into the model.
So, as you can see, there’s a lot that goes into preparing a Haptik bot to successfully cater to the needs of any enterprise, and their customers.
We’d love to hear more from other bot developers out there as to how they approach maintaining and training their bots. Please share your experiences and learnings in the comments below!
Are you interested in developing a chatbot solution for your business?

This post has been penned by Prateek Gupte, Director of Product and Engineering at Haptik.






.jpg?quality=low&width=352&name=blog-banner-2%20(1).jpg)





.png?quality=low&width=352&name=Untitled%20design%20(31).png)








-1.png?width=352&name=BlogHeader2%20(3)-1.png)

.png?width=352&name=image%20(18).png)
-2.png?quality=low&width=352&name=image%20(11)-2.png)





-1.jpg?width=352&name=Linkedin+%20Twitter%20(1)-1.jpg)




-1.png?width=352&name=LinkedIn%20(1)-1.png)
.png?quality=low&width=352&name=LinkedIn%20(3).png)




.jpg?width=352&name=sentiment%20(1).jpg)





























source on Google