

Just about 3 years ago, multiple applications which were primarily backed by conventional machine learning modules got on to the wave of optimism, driven by promising results of Deep Learning techniques.
One such application was Machine Translation which got significant improvement with an introduction of sequence to sequence learning method. Soon after, using deep learning for chatbots became a promising area of experimentation with neural conversation model becoming a starting point for developers and researchers.

With ample amount of conversational data in place and our eagerness to toy around with new technologies, Haptik, one of the largest conversational AI platform became a direct beneficiary of this research. However, it took us multiple iterations to come up with a system that worked for us in production and added significant value to the end user experience. We built a hybrid model which combined neural conversational model with graph-based dialogue system and achieved significant improvements on existing baseline systems. You can also refer our research paper, ‘Production Ready Chatbots: Generate if not Retrieve’ which was presented at AAAI-2018, Deepdial workshop.
This post primarily focuses on why we came up with a hybrid approach and how chatbots at Haptik use this approach to respond to user’s messages in a precise and intelligent way.
Before we get into the hybrid system, let’s go through some basics.
What are primary approaches to build Chatbots?
- Retrieval Approach: Retrieval based models use a repository of predefined responses and some rule-based expression match or an ensemble of Machine Learning classifiers to pick the most appropriate response.
In this category, one we use a graph-based dialogue system which helps respond to almost 70% of our user’s messages. You can refer to the details of our retrieval approach in section 3 of the research paper. - Generative Approach: Generative models are trained on human-to-human conversational history and build new responses from scratch. In our case, we use seq2seq model with 3 layers bidirectional GRU encoder and unidirectional decoder (again with 3 layers and GRU cells) with attention settings over encoder states. Details of this approach are available in section 4 of our research paper.
You can read more about these approaches.
Why did Haptik need a Hybrid of Retrieval and Generative Approach?
While our retrieval model responded to the majority of user messages, it failed on complex user queries that contained a lot of spelling mistakes, deviation from the domain, code mixed queries, etc. Hence, we decided to dive into experimenting with seq2seq model to harness our historical conversational data. By training around a million conversations, we quickly got a dirty prototype ready, which was a schizophrenic chatbot. This chatbot energetically answered all types of questions, supported every conversation, but at the same time displayed disorganized thinking which was not aligned with improving end-user experience during the conversation. Unfortunately, we couldn’t use it in that shape, because it did not adhere to the following prerequisites of building a successful bot:
- Content, tone, and personality of the bot: There was no consistency in language and grammatical constructions used by our seq2seq model; something which is not expected of a good conversational agent.
- Accuracy: While it responded to queries, as expected, it also tried responding to unfamiliar intents with unexpected responses. This defeated the entire purpose of responding accurately.
- Alignment to a specific task: Good task-specific chatbots tend to keep conversations in a narrow domain and aim to drive it towards task completion. But our model accepted open-ended queries and engaged in endless chatting.
Based on the above issues, we concluded that we needed a model which could respond to complex user queries. Also, the objective of these responses should be dedicated to putting the user back on track. And hence, navigate our graph-based dialogue system to exactly where the user left it. Hence, we started engineering a hybrid system which would use a generative model in a controlled fashion.
How does a Hybrid System work?
The graph-based system works for near-ideal scenarios and takes care of 70% of Haptik’s chatbot conversations. We introduced neural conversation model to respond to the remaining 30% of conversations where the users tend to deviate from ideal chat-flows.
We got human agents to respond in real time, with the intent to put users back on an ideal chat-flow. Interestingly, 80% of our training data comprised of these 30% conversations, while the remainder 20% was taken from rest 70% chatbot conversations. You can refer to section 4.2 of the paper for more details on our training data generation and section 5 to understand real-time working. Following is a snapshot of the real-time working of our hybrid system:
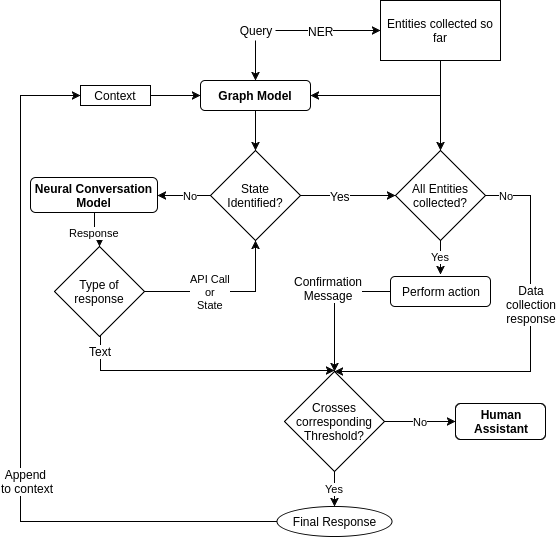
How did the Hybrid System help Haptik?
Haptik processes more than 5 million chatbot conversations on monthly basis. Here’s a list of the advantages of a hybrid model and the snapshots from reminders domain:
- We could respond to complex queries which were not handled by our graph dialogue system:

- The Hybrid System catered to hinglish (code mixed data generated by mixing Hindi and English) queries and also catered to outliers:

- It handled spelling errors, slangs and other chat lingos used on chat by Indian users:

One of the biggest advantages of being able to plug in seq2seq model was that the performance of our chatbot system was directly proportional to data.
Just like every other system, our model has its own limitations which are mentioned along with results and analysis of our system in section 6 of the research paper.
Based on our experience of iterating over and again to achieve a result oriented hybrid model, here is the list of few key checkpoints we would like other developers to consider while building a system which includes usage of the generative model.
- Clearly defined goals– As a developer and a deep learning enthusiast, it’s always fun to build generative models because sometimes the model’s behaviour is amazingly cool and brings instant gratification. But needless to say, it is important to narrow down the goal for a generative system so that you can leverage your data efficiently. At Haptik, our primary aim while building a generative system was to keep check when conversations deviate from ideal flows.
- Choice of domain– Domain defines the vocabulary which a model will need to understand. And always the lesser, the better. For example – In case you want to build a model for travel ticket booking, you should ideally prefer to train a separate model for flight bookings, train bookings, hotel bookings and cab bookings.
- Amount of Data– A ground reality of such generative models is that they need lots of data points to learn. Training data generation is one of the most critical tasks while building any neural conversation model. Getting the considerable amount of Data is difficult but a mandatory step to get measurable results.
- Standardisation of Data– Most chatbots are content heavy and messages contain a mix of static and dynamic data. Therefore, metadata throughout the system needs to be logged properly and critical entities should be tagged appropriately at the source. If not done right, one can easily end up in a situation where historical data is not reusable or it needs disproportionate time to clean it for feeding into a generative model.
We hope that this blog helps you when you decide to plug in a generative model in your dialogue systems. We keep writing about more use-cases of generative models as we plug them on Haptik as we deploy them on Haptik
Here’s a good reading list to begin with for more research on the same lines:
- Long Short-Term Memory networks(LSTM)
- Sequence to Sequence Learning with Neural Networks
- A Neural conversation model
- A Persona-Based Neural Conversation Model
- Production Ready Chatbots: Generate if not Retrieve
- The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems (2015-06)
Think we did a good job? Let us know in the comments below.
Also, Haptik is hiring. Visit our careers section or get in touch with us at hello@haptik.ai.





















.png?quality=low&width=352&name=BLOG-IMAGE-2022-FEB%20(1).png)























.webp?width=352&name=Charles-Proxy%20(1).webp)

























source on Google