

Virtual Assistants built today are expected to not just help with frequently asked questions but actually furnish end to end query resolution. In order to be able to provide a holistic & unified experience to end-users, virtual assistants need to be able to carry out these tasks instead of guiding the user or providing a DIY manual.
To support the execution of such activities, Virtual Assistants require deep integrations with multiple systems & tools. The user’s intent triggers a flurry of activities in the background which are executed by the virtual assistant in real-time.
The user only has to interact with the virtual assistant and the virtual assistant does the job of interfacing with various systems – CRM, LMS, IAM with the help of APIs.
Integrating APIs is a time consuming and yet unavoidable activity in the process of building virtual assistants. Integrating these APIs also required to follow a full SDLC (Software Development Life Cycle).
At Haptik, we soon realized that one of the biggest bottlenecks the bot developers faced was the requirement of infrastructure to run code that could integrate these APIs into the IVA.
We spent the next 3-4 days in research and came up with a working solution of overcoming these problems. We wanted to find out ways to overcome this bottleneck while still maintaining proper logging, error handling, and reducing the time and effort.
FAAS – Functions as a Service is something what we wanted to build out and integrate.
Below is all the Research we conducted and how we finally ended up building the solution. Some of the paragraphs in the blog would also show how we were thinking about each and every phase etc.
Research Phase
This particular project was divided into 7 major parts:
1. Identifying the backend tool to execute the code.
2. We would go ahead with already available tools or services in the first phase, with refactoring and improvements in V2.
3. Identifying API contracts for this microservice (It ended up being a nano-service).
4. Move existing code in our Integration repository to this setup via backend with the help of our Implementation team.
5. Sandboxing the code executor (for different environments, support for frameworks, etc.). Building both testing and production executors.
6. Make it easy to add and maintain libraries
7. Returning an API endpoint which will run on certain triggers during IVA flow
8. Making this process simple even for a non-developer.
Criteria for Technology selection
1. Initial Setup time & Management of the new service2. Costs
3. Creation of function and easy execution of code
4. Easy integration with our IVA/Bot builder
5. Scalability
6. Ease of Deployment of new code & Monitoring
7. Security
We came up with 7 possible solutions.
We will start with solution 2-7 and then come to solution 1 which we in the end also locked down on.
The below tools are actually amazing to solve many use-cases. In this particular scenario did not suit our use-cases.
Solution 2 – AWS Cloud 9
This is AWS’s Cloud code Editor solution where you can collaborate on writing code and finally deploy the code as an API Gateway Endpoint, which can be put directly into our Dialog Builder tool while building an IVA.Pros
Simple to use
Cons
- 1. AWS console access required for everyone who is Building an IVA and wants to integrate Code/APIs.
- 2. Manual effort of publishing to API Gateway.
- 3. Management overhead.
- 4. You can read more about Cloud9.
Solution 3 – OpenWhisk (4k+ stars on GitHub)
OpenWhisk is an Apache Incubator Project. Below is based on when we were researching.
Pros
- 1. Open-source
- 2. IBM uses this on their platform.
- 3. New code could be added via an API and that piece of code can be called via an API.
- 4. Support for logging available out of the box.
- 5. Supports environment variables and custom packages.
Cons
- 1. No good UI to manage.
- 2. Infrastructure management – When new functions are created, it creates Docker containers in the backend and they require infrastructure to run. Not just maintenance but scaling would need to be thought out.
- 3. Open-source, and requires regular upgrades, which could become a significant overhead given that the team is quite lean.
- 4. OpenWhisk does not provide versioning by default. The application code will have to handle it by giving an appropriate package and action name.
If you want more details around OpenWhisk, do mention in the comments, or connect with me. I would be happy to share more details.
We got a prototype of this up and running and got 20 sample functions running as an API as well.
Solution 4 – Fission (4k+ stars on GitHub)
Fission is a framework for serverless functions on Kubernetes – Add Link.
This was another open-source solution that was being used by the community. It had a great UI and made management easier as well. The cons were similar to OpenWhisk on the management side.
Pros
- 1. 100 ms cold start seemed to be quite fast.
- 2. Maintains a 3 pool container environment by default.
- 3. Support for custom container images on the go.
- 4. Full Kubernetes support & namespaces.
- 5. UI support
Cons
- 1. Management & Infrastructure
- 2. Keeping up to date with the latest releases.
- 3. HTTP API for getting metadata missing. So, if I need details for a function I created, it can be done via a subprocess call. Fission CLI needs to be present.
Solution 5 – OpenFaas (15k+ stars on GitHub)
OpenFaaS is Kubernetes-native and uses Deployments, Services, and Secrets. For more detail check out the “faas-netes” repository.
Pros
2. Available as a Managed service OTB – Costs higher
Solution 6 – Kubeless (5k+ stars on GitHub)
Kubeless is a Kubernetes-native serverless framework that lets you deploy small bits of code (functions) without having to worry about the underlying infrastructure.
According to them, they are better than Fission and OpenWhisk.
Again similar Pros and cons like other tools we discussed above. Finally, we dropped it.
Solution 7 – Simple Docker containers running code
Containers could be used with ECS task scheduling which is triggered when API call is done, OR by keeping the task running at all times. However, this defeats the purpose of going serverless, so we dropped this idea as well.
And now for the Final Solution and the solution which was the first we came up with:
Solution 1
AWS Lambda + API Gateway
Using AWS Lambda reduced the overhead of managing infrastructure and going fully serverless.
We finally chose to go ahead with the AWS Lambda, API Gateway based Hybrid solution. We have already done most of the research here and things seem to be working.
The way this would work is:
IVA/Bot Builder -> Machine Learning Pipeline (execution trigger) -> Code-Executor service -> AWS API Gateway -> AWS Lambda
We divided the project into 2 major phases. The first phase was the Rollout with the basics of code execution. The second phase was to integrate without Dialogue Builder so that any IVA builder could easily use this and view logs for the same.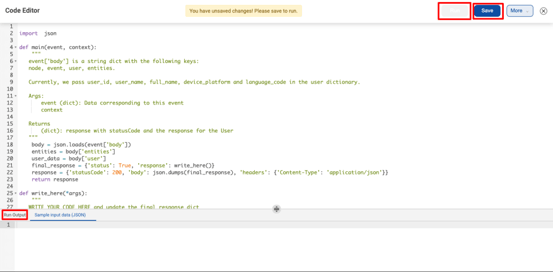
Phases of Development
Phase v1.0
Outcome: Should be able to write an integration function and execute it on a FAAS. No versioning will be supported in V1.
- 1. List existing integration functions we could port to code executor first
- 2. Get an idea of what all resources and packages are needed by integration functions.
- 3. Integrate this function with the pipeline and probably test with the bot
- 4. Fix Container image / Layer of packages that are to be used (Packages basis above research)
- 6. Test functions locally
- 7. Limit amount of resources a function can use CPU, Memory, Disk
- 8. Stdout of the lambda function (API Gateway identifier)
- 9. Show current code in the UI as well
Additionally, some good-to-haves:
- 1.How can we inject environment variables? (ENV Manager/KMS/Vault etc.)
- 2.Bot/IVA level store env keys on Mogambo or an ENV
- 3.How do we access Datastores?
- 4.Come about with a deployment plan
- 5.Monitoring for execution failures
We really wanted to get v1 for code executor up and running within a few days. So for this, we discussed that we should go with a more cloud agnostic open-source method but on further evaluation, we realized that handling deployment for these open-source options is quite complex to get started with. This is a process that is typically done by companies like IBM which have very large teams.
And also the open-source methods sometimes lead to management overhead.
Technical Implementation
The major change was that we deployed the backend for this code executor pipeline in a separate repo as a separate nano-service.
This was a Django project and could be deployed on any cloud platform later in a scalable way. The repo mostly contains all Boto3 code and some pseudocode which we took reference from a couple of places which saved us some time.
The deployment solution for this service is a Hybrid one. We planned to deploy this on AWS itself and also test it out on Azure on-the-side. We are on our Journey to migrate lot of our Workloads to Azure so we wanted to try out how this would work in an Azure specific setup.
(Later in version 2/version 3 we can try and move to Azure Functions etc. Python3 support was in Beta on Azure Functions that time)
Also, later if we were to move to open-source methods, we can directly make changes in this service itself while still maintaining the API contracts our Bot Builder was expecting.
The whole idea is to get V1 out there ASAP.
Phase v2.0
Outcome: Fully functional code executor with least management overhead.
- 1. Figure out versioning & Scaling & Executability
- 2. Logging – Viewing logs of the Code for testing and also when it runs in production
- 3. Libraries/Methods Pipeline – Devs can keep adding packages
- 4. We built a common Haptik Code Library Repository to handle this.
- 5. Local Testing – Dev testing and logs like Mogambo
- 6. Versioning for Functions and APIs
- 7. Give developers a standard Docker image they can use to test functions ()
- 8. Datastore method to access Datastores
Code Executor Flow & Consumption of APIs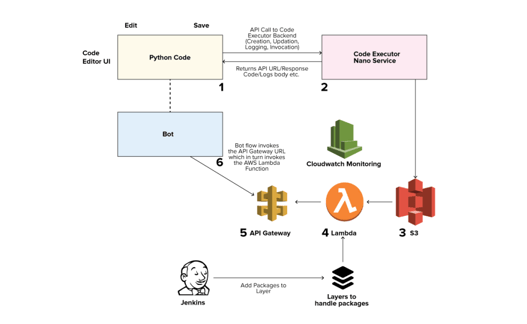
- 1. The UI interface, (Bot Builder for now) has a code block. The IVA Builder user will paste
- 2. Python Code inside the block and click save.
- 3. On the UI interface, there is a Syntax checker that will check the code Syntax and save the code thereafter.
- 4. Environment variables are passed along with the code save.
- 5. On Clicking save, the Code executor create_function API call is made which:
- 6. Pushes the saved code to S3 as a ZIP & create a function on Lambda along with the CloudWatch logging setup.
- 7. Also, using CloudFormation, an API gateway stack is brought up and API URL is returned as HTTP response as described in our internal documentation.
- 8. The API URL is the one and only way to execute the function. POST call to API URL for invoking the Lambda Function.
- 9. Execution Logs of every Code Executor blog is visible on our IVA Builder itself.
Some Problems that we faced
- 1. Default limits of AWS on number of Lambda functions that can be created
- 2. Default limits of AWS on the number of API Gateway endpoints that can be created
- 3. Adding/removing libraries on the go in the Layers of Lambda.
Some additional changes we made:
Dropped usage of API Gateway
Instead of executing the API Gateway, using restricted AWS credentials, we build functionality to trigger the Lambda function directly, and this way we never had to expose any public/ private endpoint. The function name was anyways available to us in our IVA/Dialogue builder tool.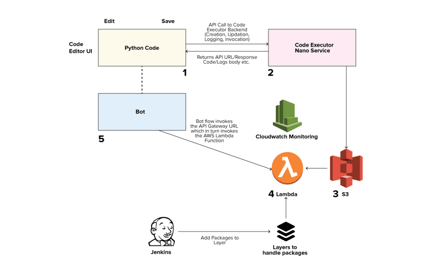
Support to make Lambda functions run within the VPC
Earlier all functions were executed outside the VPC and whitelisting for the outgoing IP via NAT could be done. Running within VPC has some cold start issues but things have been working fine so far, and creating functions inside VPC is optional.
Stats
1. We have over 5000+ code executor blocks in our IVA builder and all run at scale without any intervention from our Engineering teams.2. A few $$s spent for millions of executions per month.
3. Accessible for our cloud Agnostic platform deployments on Azure too
4. We are planning to add more security-related features and easier ways to add more packages and support even more frameworks in the future.
See the code executor in action & how we have productized this further.
Further, I wanted to thank @viraj-anchan for his valuable contribution to this Project.








































.webp?width=352&name=Charles-Proxy%20(1).webp)


























source on Google