

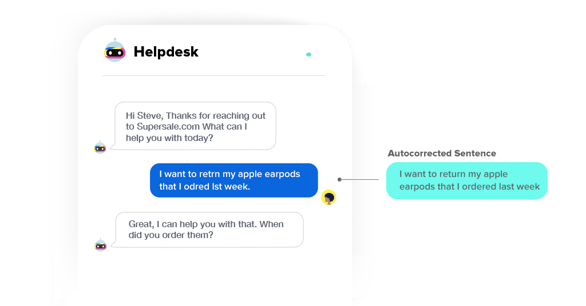
I am sure I won’t make a spelling mistake while writing this blog. But unfortunately, it’s hard to expect the same while chatting, tweeting or commenting or social media. IVAs (Intelligent Virtual Assistants) built on the Haptik platform have to cater to such noisy queries and still provide quick and correct resolution.
Hence, a fast and accurate spell corrector is one of the fundamental components of our NLU pipeline. We are happy to share our spell correction module, “Spello” and some of our learnings from the same.
Spello is a spell correction model that uses the power of three models “Phoneme”, “Symspell” and “Context” in the backend to get the best possible spelling suggestion for misspelled words in a text. The Phoneme Model uses the Soundex algorithm and is responsible to suggest corrections by searching for similar-sounding words. Symspell model uses edit distance and suggests correction primarily for unintentional mistakes while typing from the keyboard. The contextual model is responsible to find the best candidate from the list of suggestions suggested by Phoneme and Symspell model for a misspelled word. Currently, Spello is open-source, ready to use for English (en) and Hindi (hi) and fast enough to correct misspelled words in less than 10ms.
Available Models
Below is the detailed description of the working and types of mistakes handled by each of the above-mentioned models: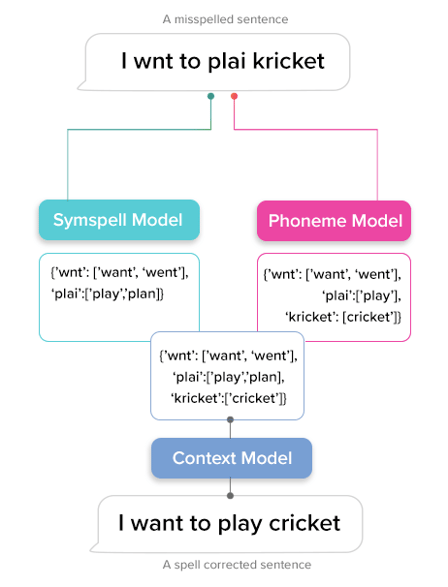
- Phoneme Model:
This model handles spelling mistakes that occur either due to wrong usage or omission of vowels in a word.
For example:
Check for availblity -> check for availability pls book a table -> please book a table सही मातरा में पानी मिलाएं -> सही मात्रा में पानी मिलाएं |
- Symspell Model
We are using a modified version of Symspell model to handle qwerty based errors which un-intentionally occur while typing from the keyboard. Below are some of the typing mistakes users might make in a conversation:
Adjacent Character error: Misplace a character by some nearby character from the keyboard.
For example:
training -> trsining (here “a” get replaced by “s” which comes adjacent to each other) |
Transpose error: Sometimes while typing fast, we might introduce transposition between characters.
For example:
helping -> hleping [here “el” get replaced by “le”] |
Adding or deleting unrequired character: While typing fast, sometimes users end up adding extra character in a word.
For example:
address / addres -> addresss [here an extra “s” gets added in word] |
Context Model:This model helps to determine the most probable word from the list of the suggested word for misspelled words from the Symspell and Phonememodel. A lightweight n-gram probabilistic model has been trained which will find the next best word in a sentence. We use this model to calculate the overall probability of a sentence being formed for each combination of the misspelled word suggestions. For example:
For the sentence, “I wnt to buk flight”, we got two misspelled words ‘wnt’ and ‘buk’ with suggestions [‘went’, ‘want’] and [‘book’, ‘buy’] respectively. This model will calculate the probability for each of the following sentences:
I want to buy a flightI want to book a flightI went to buy a flightI went to book a flight |
The sentence with the most probability will get selected and the suggested words in that sentence will be selected as the correct spellings of misspelled words.
Getting Started
Install the library using pip:
pip install spello |
Initialize the model by providing language code:
from spello.model import SpellCorrectionModel sp = SpellCorrectionModel(language='en') |
Train the model either by giving a “list of sentences” or “word count dictionary” as training data:
| sp.train(['I want to play cricket', 'Kohli scores another century']) sp.train({'I': 2, 'want': 1, 'play': 1, 'cricket': 1, 'century': 5}) |
Run the model for spell correction:
sp.spell_correct('i wnt to plai kriket') { 'original_text': 'i wnt to plai kriket', 'spell_corrected_text': 'i want to play cricket', 'correction_dict': {wnt: 'want', 'plai': 'play', 'kriket': 'cricket'}} |
Pre-trained models for English and Hindi are available to be used directly and you can train models in other languages as well. For more details, follow the Github repository of our Spell correction – https://github.com/hellohaptik/spello
Limitations
There are two limitations of the current version of Spello (spell correction):
1. It assumes that words that are part of training data are correctly spelled words. However, the frequency of misspelled words being lesser will reduce their impact on the model if the frequency of their respective correct version is higher.
2. It attempts correction for only those words which are not present in vocabulary. For example, In a sentence “I want to by Apple”, Correct replacement for ‘by’ should have been “buy” but it will not suggest any correction for “by” as it is a valid English word and is very likely to be present in the vocabulary when you train the model. However, we have seen negligible occurrences of such mistakes in user data at Haptik and hence we avoid correcting such words to optimize the speed of processing in a production environment.
In a future release, we will be adding features to address both these limitations. Do let us know your feedback and we will be happy to consider it while building our future roadmap. Haptik is hiring. Do check out our careers page.





















.png?quality=low&width=352&name=BLOG-IMAGE-2022-FEB%20(1).png)






















.webp?width=352&name=Charles-Proxy%20(1).webp)


























source on Google