

Last year exposed all of us to a global uncertainty no one ever anticipated. It cost us billions of lives and posed new challenges for economies to survive. At the same time, it also highlighted the need for innovation as healthcare workers and other professionals stepped up to adapt to the new normal & selflessly help others.
We at Haptik also did our bit to help during the pandemic. We built the official MyGov Corona Helpdesk, the world’s largest WhatsApp chatbot for the Indian Government. We made this chatbot within five days to help answer queries of 25 million+ users and tackle the spread of misinformation.

Innovation and disruption have always been the key to Haptik’s success. Our team showed incredible persistence in between all the chaos and challenges by putting in continuous effort into research and development to push conversational AI boundaries.
The applied research focus at Haptik on the following tracks -
- Contextual and precise conversations
- Data efficiency and continuous learning
- Pushing boundaries of NLU
We conducted several experiments in all the mentioned tracks to add significant value for our end customers. Here are our top highlights from each of the ways mentioned:
Towards contextual and precise conversations
- Although building contextual assistants remains an overarching goal, most virtual assistants get consumed in the greed of answering as many users queries as possible. Instead of optimising higher automation at the cost of end-user experience, we started the year with an initiative to enable Haptik’s IVA to probe for clarifications and confirmations from users in a graceful way NLU models are not highly confident. These capabilities were further available to platform users in the form of Smart Assist, and it gave a significant upgrade to 9% of experiences where AI models needed assistance in disambiguation.
.jpg?quality=low&width=900&name=IVA-Screenshots%20(1).jpg)
- Identifying user intent is one of the most critical components for contextual conversations. While most conventional platforms focus on improving accuracy by training intent detection models on user utterances from the training data, we explored the usage of bot utterances to improve our accuracy. By taking into account the specificity between user utterances and bot utterances, we could push our f1 score by 5% without the need for any additional training data from bot developers.

Towards data efficiency and continuous learning
- We all know that generation of paraphrases using GPT-2 / 3 was delightful to see in Jupyter notebooks and OpenAI playground. At Haptik went a step ahead and created an algorithm to automatically rank paraphrases and select less than five paraphrases per original data point, and still maximise the intent identification model’s performance.
- Haptik’s conversational AI platform does so by using paraphrases to probe the model trained on original data.
- We also ensure the diversity in paraphrases with the help of entailment score and BLEU score and manage to keep the noise under 10% in augmented data.
While we currently use the GPT-2 model fine-tuned for paraphrase generation, and it helps us bring down data requirements by 33%, we love the way progress in NLG is helping NLU, and we are on our path to reduce seed data requirement even further with the help of GPT3. Do watch this space for more as we will share our work this year as we make progress.
- While we ensure that our platform provides the highest accuracy with minimal seed data, it is pretty established that nothing can teach a model better than actual user queries. On production, virtual agents are exposed to diverse user queries from various demographics. These queries spread across several existing and unforeseen intents that may not be in the scope of seed training data. To ensure an efficient feedback loop, we built an AI recommendations module to discover new user intents with more than 85% accuracy and provide a faster way to improve virtual agents. We believe that this is a significant step towards the future of truly self-learning virtual agents.
Towards pushing boundaries of NLU
- Pushing the research community towards more realistic NLU models’ benchmarking, we introduced and open-sourced a new dataset called HINT3 and presented the same at EMNLP 2020. We also introduced a method to create complex train sets to enable benchmarking over scenarios of imbalanced datasets, granular labels, and unintended correlations in the data.
Furthermore, our Datasets and methods were also recognised by researchers at IBM Watson to benchmark their capabilities alongside Haptik and other global technology leaders.

- In a world where building larger language models and complex NLU pipelines are ubiquitous, our team truly believes that sharing weights across multiple tasks is a more sustainable and efficient way to build NLU architecture moving forward.
To help the machine learning community with the same, we open-sourced the framework to quickly enable researchers and engineers to prototype their NLP tasks in a Multi-Task-NLP setup. While this framework is currently in a nascent stage, we hope it motivates the community to innovate further to build more efficient training and inference architectures.
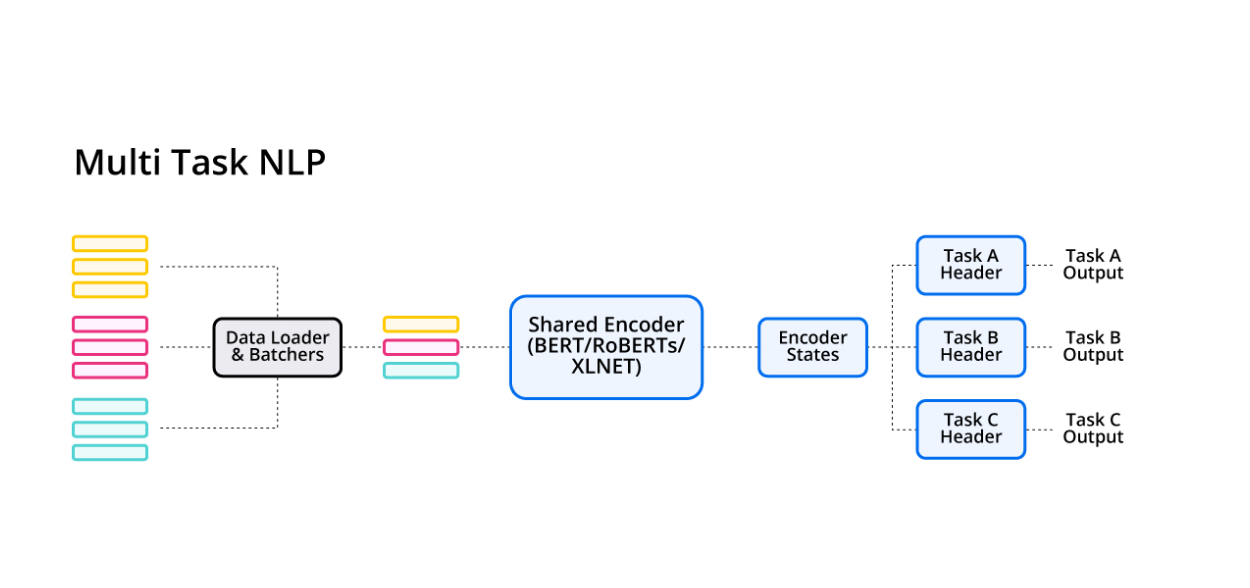
To ensure that all our customers and end-users get the most impact from the progress of our AI initiatives, our product teams migrated more than 200 Virtual Assistants from conventional dialogue systems to state-of-the-art systems.
While the team at Haptik is committed and focused on pushing the boundaries of Conversational AI, we are able to do so with Fastai, Huggingface and Openai frameworks, and we are thankful for the same. With great support from our customers, the AI research community, and our fantastic engineering team, we at Haptik are confidently looking forward to pushing AI’s limits to build great conversational experiences in the time to come.
If you wish to join us in our journey of enabling great conversational experiences, do explore Careers at Haptik. We are hiring!
.png?quality=low&width=352&name=BLOG-IMAGE-2022-FEB%20(1).png)













source on Google