

Take a look at the video below, the solution in play is what we’ll be explaining through this write up. Notice the processing at the bottom of the screen grab to better understand the solution.
Now that you’ve looked at the video of the solution in play, let’s understand how we get here! Haptik focuses on developing a deep understanding of natural language and domain intelligence as a leading provider of intelligent assistants, including voice-enabled ones. When it comes to speech recognition in Voice Assistants, we rely on device libraries or third party APIs that include Android default Speech Recognition, iOS Speech Recognition or API providers such as Azure/Reverie/Google.
We discuss in this blog how Haptik uses domain intelligence to solve speech recognition inaccuracies across domains in third party speech recognition systems.
Let’s understand the problem statement
Improving the accuracy of third party speech recognition solutions to better cater to user intent. At Haptik, we use a layer of domain intelligence based post-processing of the output from third party speech recognition solutions to better understand and accordingly fetch results for the right user intent. For example, if a Voice Shopping Assistant user says "Laung" and the Third Party system's top interpretation is "long," we can recover from the error and correct it back to "Laung." This suggestion is made based on contextual understanding of the term which makes more sense in the grocery domain.
Understanding Speech Recognition APIs Output
Almost all Speech recognition APIs return the top N interpretations along with their confidence scores.
Example Output if a user speaks out the query “Vaseline”
Vaseline (0.342865258455), westland (0.115404672921),
westlin (0.0663541182876), West Lane (0.0444444417953),
wrestling (0.0444444417953), vesselin (0.0444444417953),
westling (0.0444444417953), westlund (0.0444444417953),
westline (0.0444444417953), West line (0.0444444417953),
West plane (0.0444444417953), waistline (0.0444444417953),
vestland (0.0444444417953), westerlund (0.0444444417953),
West Linn (0.0444444417953)
Deeper Understanding of the Problem
We took a live Grocery Ordering Voice Assistant for our client as the test bed for building out this feature. Let’s take a look at the performed analysis:
Types of queries being received on the Grocery Ordering Voice Assistant
These were found to be largely queries by category, brand or specific products.
Kayam Churan for pet Dard
fruit and nut chocolate
Dairy milk
3 kilos of tomato
Joy lotion 50% off
show maximum discount
Vaseline
Hide and Seek choco rolls
Maggi Masala Indian flavour
please add 3 Ghadi detergen
Surf
Q) How many queries have speech recognition issues?
A large percentage (above 30%) were found to have speech recognition issues.
Q) In what percentage of queries with speech recognition issues was it humanly possible to identify the correct query?
Human identification was found possible in almost 75% cases. This would be the approximate upper limit for improvement in Speech Recognition interpretation through post processing after the response is received via APIs. The reason behind this is simple. If a human with domain understanding is not being able to identify the correct interpretation of the user query, a machine would definitely find it difficult.
Examples of Cases with correction humanly identifiable.
red chillies holes -> red chillies whole
casio nuts -> cashew nuts
hand seming tyzer -> hand sanitizer
needless -> noodles
bainjal -> brinjal
send fuel oil -> sunflower oil
loosu chini chahie -> loose chini chahie
mujhe Les lena hai -> mujhe lays lena hai
pasi paruppu -> pesarapappu
Examples of Cases where user intent was not understood even by a human.
Udan mata
Macons
Wam
Shri
Q) In how many cases was the best interpretation provided by the ASR incorrect while the other probable interpretations had the correct option?
Around 30% of the speech recognition errors were found to contain the correct interpretation in the probables.
- Red Chillies holes -> absent
Casio nuts -> absent
hand seming tyzer -> absent
Needless -> present
Bainjal -> absent
send fuel oil -> absent
Pepsodent Baso gram -> absent
loosu Chini chahie -> present
Mujhe Les lena hai -> present
Pasi paruppu -> absent
Formulating the Solution
We figured that there were three directions in which Speech Recognition could be improved after the response is received from the Third Party API.
1. Selecting the probable which is most relevant to the domain.
- 2. Correcting based on phonetic similarity to known domain words.
- 3. Learning common Speech to Text errors which were repeating in the data.
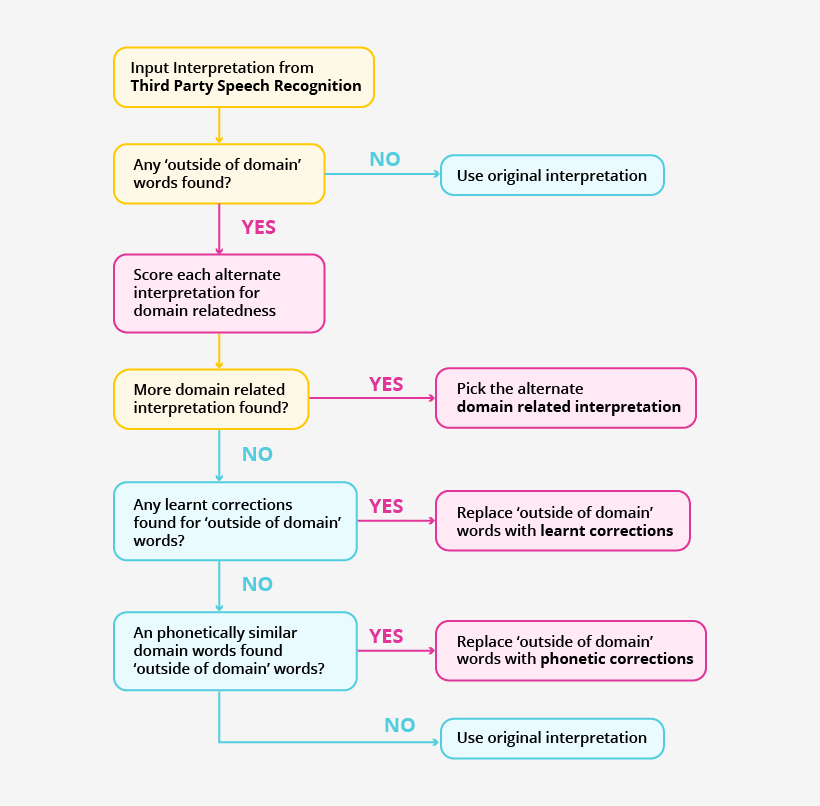
Implementation & Learnings
Selecting the probable which is most relevant to the domain
Domain specificity means that our Conversational AI models are based on the learnt ontologies for each domain. These include all concepts important to the domain such as subcategories (e.g. balm, spread, shower gel, shampoo, toothbrush), features (e.g. spicy, loose, brown, chocolate favoured),Brands (e.g. Tropicana, MTR, Cadbury, Fevicol) and more.It also understands common query patterns in the domain - e.g. ‘I want to buy milk’, ‘mujhe hari sabjiyan chahiye’, etc as well as the synsets for common words - e.g. buy = purchase = kharidna etc.This structure enables us to identify which query interpretations are more domain related.
- For each interpretation, we compute a domain specificity score.
- For each word in the query found as a category, brand, feature or product name word a high score is given. E.g. Cashew, mango, pickle, bourbon etc.
- For each word belonging to common queries but not a part of domain words, a medium score is given. E.g. i, want, buy, have etc.
The highest scoring domain specific interpretation is then taken to be the correct one.
Challenges faced in this approach & learnings
There were 2 major challenges faced in this approach:
- Maintaining a balance between domain specificity and speech recognition confidence scores.
Correcting as many incorrect interpretations as possible to more domain specific ones can result in correcting already correct interpretations that can really break the user experience. To avoid this, we put a threshold to only try correcting if the original query did not have a high confidence score or was not already sufficiently domain specific. This allowed us to recover back parts of the speech recognition accuracy while making sure that no additional inaccuracies were introduced by this algorithm. - Domain specificity calculation can lead to a larger score for interpretations with more words. E.g. pasty Colgate got corrected to face ke colgate because the correct interpretation paste colgate had lesser number of words and consequently a lower domain specificity score. We overcame this by introducing a length normalization while computing the Domain Specificity Scores.
Learnings from this project so far:
-
Trying to correct based on phonetic similarity to known domain words.
This approach is based on the hypothesis that if we take the interpretation of the Speech Recognition system and correct all words which were not understood to phonetically similar words in our domain knowledge, we can change some of the incorrect interpretations to correct ones.
We implemented multiple phonetic similarity algorithms including soundex, metaphone etc. Among these, soundex performed best but overall we found the correction accuracy via this approach was very low. What that meant was that while phonetic correction did correct some of the words, in most cases it faltered by correcting to some other similar sounding word. Ultimately this approach was dropped from the end solution.
- Learning common Speech to Text errors which were repeating in the data.
One of the things we saw from a visual scan of the user conversations was that people have a tendency to try repeating themselves more slowly and clearly if their query is not understood by the Voice Assistant. This was an in-depth data set to learn speech recognition errors from.
We identified all queries where the user changed the query after being misunderstood by the Voice Assistant. To avoid scenarios where users indeed changed their query to something else entirely and were not really repeating the previous query, we put a restriction to consider corrections happening within 30 seconds of the first query. A phonetic similarity threshold was also added to further strengthen the restriction.
This led to a significantly sized library of learnt corrections e.g. the tall -> dettol, siltod -> cinthol, dappa -> dabur, hair ji -> hair gel, painting -> pantene etc.
Conclusion
The above implementation was able to yield a significant increase in speech recognition accuracy compared to using the underlying domain agnostic speech recognition APIs directly.
Furthermore, the team is continuing to improve this solution including usage of phrase context to prioritize corrections and improvement in terms of managing phonetics based corrections.








































.webp?width=352&name=Charles-Proxy%20(1).webp)


























source on Google