
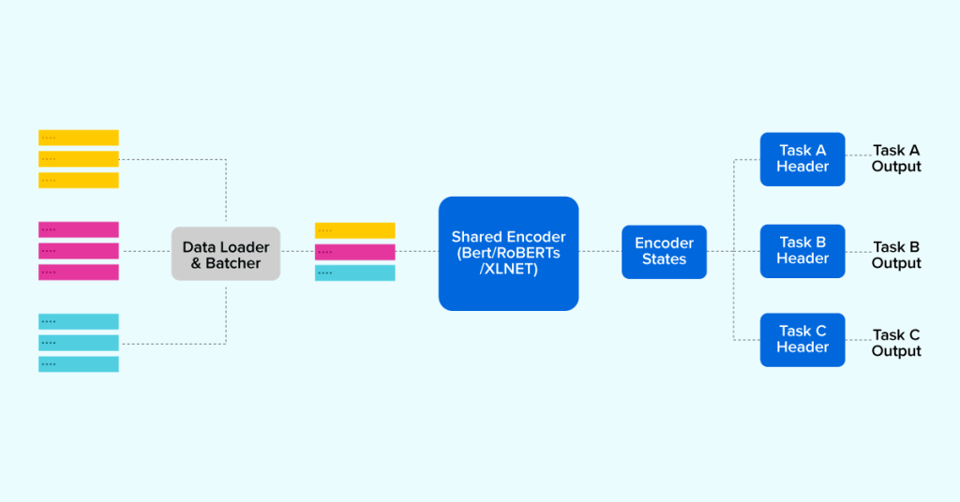
We recently open-sourced a repository called Multi-Task learning which can help with multiple conversational AI tasks. In this blog, we have explained why such an architecture can change the way we build conversational AI systems and the thought process behind building it.
Entrusted to build the Next-generation conversational AI, we had some obvious questions to contend with.
How do you define “a good conversational ai “? What does it comprise of? What are the indispensable cogs in this machine?
Drawing parallels to the human brain and its conversational ability, was inevitable in this discussion. One of the résponses : “it should have Natural Language Understanding (NLU) + Natural Language Processing (NLP) + Natural Language Generation (NLG) abilities “, was met with an eerie silence, followed by a thought-provoking counter question.
“ Does the human brain handle conversations the same way? If yes, How does the transition between the three, seem so fluid? Almost unnoticeable? Why do we not feel any lag between the 3 processes? “?
Following a bit of research, it was not very difficult to find out that there are 3 areas in the brain which do exhibit similar behaviour .
Wernicke’s area: mainly involved in the understanding and processing of speech and written language. The NLU equivalent?
Angular gyrus: helps with memory retrieval, context understanding, and general cognition. NLP (pragmatics, context understanding /knowledge retrieval) equivalent?
Broca’s area has an important role in turning your ideas and thoughts into actual spoken words. The NLG equivalent?
And?
There was no way for us to profess with certainty how these three operate in sync, for humans to comprehend a query and respond back with the appropriate answer.
But an argument in the context of intrinsic, extrinsic and germane cognitive load, gave us some validity to our assumption that ‘maybe’ general conversations do not exert cognitive load large enough for the aforementioned lag across these processes to be noticeable. The Argument was beautifully underpinned by an example of a bilingual conversational exercise where a bilingual user is being asked a question in one language but needs to respond in a different language.
The ‘Understanding act’ in a foreign language, ‘processing/retrieval part’ in the native language, and responding again adds a bit of extraneous cognitive complexity, causing the minuscule but noticeable lag, enough to ascertain that we could assume the fundamental pipeline for conversational AI to look something like:
NLU-> NLP -> NLG
The mind works by ear
Language Understanding is easier than a generation, in general. Lots of people comprehend a second/third language really well, but can’t speak with similar fluency. In fact, the study of brain activities against the sound using the Magnetoencephalography (MEG) technology has demonstrated that it is even possible for human infants to start to learn/understand 2 languages together, while still not being able to speak any.
That pretty much made it clear to us, we needed to take up NLU before the rest.
With NLU encompassing syntax, semantics, and pragmatics, we zeroed down on the bare minimum requirement for a functional NLU system for conversational AI. Each component plays its own role in ensuring the virtual assistant sounds intelligent and not vulnerable to very common failures. Each cog in this machine is designed to either detect, extract, or infer from the query to intelligently respond to the user.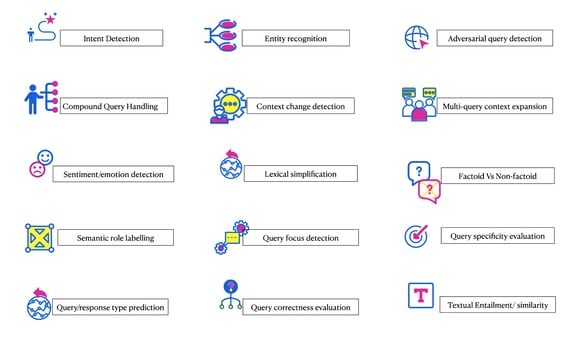
The Centipede’s Dilemma
“The centipede effect occurs when a normally automatic or unconscious activity is disrupted by consciousness of it or reflection on it. For example, a golfer thinking too closely about her swing or someone thinking too much about how he knots his tie may find his performance of the task impaired.”
Considering the spectrum of functionalities expected(as seen in the diagram above) to be developed for an effective natural language understanding required in a conversational system, putting it all together can be no lesser than ‘the centipede’s dilemma’ for an AI developer. Imagine the complexity of the pipeline if each component was driven by GPU-hungry transformer-based architecture. Imagine the need to upgrade to the latest SOTA encoder, every few weeks. Needless to say, it can easily bog down most developers.
There was a dire need for a utility which is capable of performing multiple conversational tasks without hogging on computational resources and be versatile enough to fit the needs of different data formats.
Having a closer look, it’s probably a bad idea to make a separate model for each task and carry along the burden of millions of parameters each time. We found a simple yet effective way to do this is by having a pre-trained encoder model act as pivot and then build task specific headers on top of it as required.
Vola! one can now get rid of those heavy encoders required for each task by clubbing multiple tasks together.
The following illustration demonstrates the gist of how multiple tasks can be trained using one single shared encoder: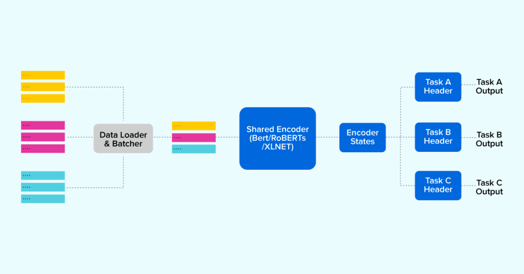
The Swiss army knife – Introducing Our Multi-Task NLP
In a bid to make life easier for NLP developers, we started to put together a toolkit which is capable of single/multi task learning and also aiding them with the development/ deployment chores. We feel it’s the ‘swiss army knife’ moment in our conversational AI journey.
The following are some major development concerns which this toolkit addresses:
- 1. Enhanced maintainability of conversational pipelines
Does a multitude of NLP models in your pipeline make it look like a jigsaw puzzle? Do you struggle to put the pieces together and make it work? Well, no more! With our toolkit, you can build a single model capable of performing multiple tasks hence sparing you the pain of managing ‘n’ number of models in one place. - 2. Reduced GPU infrastructure consumption for deployment
- It takes a lot of engineering effort and infrastructure cost to deploy and maintain a pipeline containing multiple transformer-based GPU hungry models. Using this toolkit, tasks can be easily clubbed together to keep the model count low while keeping the tasks capabilities intact.
- 3. Faster inference for multiple conversational components
- Is the inference latency requirements restricting your conversational system from having more features/ capabilities ? We provide a simple inference pipeline which can batch (pack) inputs of multiple tasks together for simultaneous inference. This can reduce inference times significantly alongside reducing resource consumption.
- 4. Better learning with comparatively lesser data
- As the learning space for multiple tasks are shared due to the presence of a single pivot model, similar tasks put together can learn better with lesser data.
There’s more!
- 5. Versatility to cater diverse NLU requirements .
Diverse conversational use cases have diverse needs too! For example, textual entailment and intent detection have different data format requirements and belong to different task families. A down-side to this is every time a different family of tasks is to be modeled, a new setup is required to be done.
Our toolkit provides versatile data formats and encoder model types to fit the diverse needs.
We believe most of the NLU tasks can be accomplished if formulated as one/ multiple of these task families.
- a. Single sentence classification
- b. Sentence pair classification
- c. NER/ Sequence labeling
- 6. Easy setup of train/ infer for tasks with no need to code.
So, will the toolkit be difficult to use? Not at all! One can train a model in three simple steps. All the selections, be it the data format or encoder model choice, can be done just by changing names in the task file defined for training, so no need to code for it!!
And not to forget, the super simple infer pipeline which can directly load and infer upon a multi-tasks or single-task model.
The Humphrey’s law
Jeff Sutherland’s version of Humphrey’s Law states that “users don’t know what they want until they see working software”
We’ve open-sourced the toolkit so everyone can use it for building great conversational systems. To demonstrate the effectiveness of our toolkit, we’ve curated some ready to use examples of conversational tasks, to be trained over some of the popular public corpuses. Below are some sample use-cases:
- 1. Answerability prediction (single task, single query classification task family )
- 2. Textual entailment (single task, Query pair classification task family )
- 3. Intent detection + Named entity detection + Fragment detection (Multi – task setup , multiple task types)
- 4. Query grammatical correctness (Single task, Single query classification task)
- 5. Named entity recognition + part of speech tagging ( Multi-task, Sequence labeling task family )
- 6. Query type detection (single task, single query classification task family)
- 7. Sentiment analysis (single task, single query classification task family )
- 8. Query pair similarity ( single task, Query pair classification )
Details for these Humphrey’s law can be found here.
Whether you’re an AI practitioner getting started with NLP for conversational AI, or a seasoned NLP expert, you can easily build your conversational use case(s) as a single task or put multiple tasks together to train/ infer a single model. To experience how simple it’s going to be, pick up an example notebook, and get going in 3 steps without any need to code!!
We’re looking forward to adding support for generative tasks as well. This will remarkably enhance the toolkit’s robustness to model conversational tasks. NLP developers can go through the step by step guide present in our documentation to understand bits and pieces of the toolkit. We encourage them to experiment around with different tasks and encoder types. In case, one faces any issue, please feel free to raise it on our https://github.com/hellohaptik/multi-task-NLP.
What lies in the future?
Multi-task-NLP is just one of our many initiatives in the quest to find simpler, effective ways to build better conversational AI systems. The future of AI agents is to be multilingual, multi-tasking, multimodal. Multi-task learning did open a new avenue for building efficient NLU models, but at present each task is essentially independent. For NLU-NLG duality, the Multi-task learning paradigm will need to be extended for a dependent , ordered tasks.
There is empirical evidence that people with multilingual skills are better at multitasking and they can learn comparatively quicker than monolingual individuals. .As Computational neuroscience discovers better theoretical abstractions and mathematical models for language abilities of the human brain, it might pave the way for better learning algorithms and network architectures which can solve conversations at scale, with near-human accuracy.





















.png?quality=low&width=352&name=BLOG-IMAGE-2022-FEB%20(1).png)






















.webp?width=352&name=Charles-Proxy%20(1).webp)


























source on Google