

In 2026, voice AI agents have moved from being an item under innovation budget to being top on the infrastructure budget. It sits in boardroom decks alongside cloud strategy and cybersecurity posture - not as an experiment, but as a capability worth owning. Even the question raised by enterprises has changed: “Should we deploy voice AI?” to “Why is our voice AI agent performing below expectations?”
The answer, almost universally, is scale.
The gap between a successful proof of concept (POC) and a production deployment that delivers at enterprise volume is one of the most consistently underestimated challenges in the space. While the underlying models are capable, the gaps in the system are manifold: organization-readiness, architecture, integration, and data governance.
Together, it’s the difference between a system that impresses in a controlled environment to one that truly delivers under contact center conditions: unpredictable traffic, dynamic knowledge, regulatory complexity, and millions of customers with no interest in deployment timelines.
This piece is for the enterprise that is past the "what is voice AI" conversation. What follows is the change that follows after 10 million calls, and the required design for before you get there.
The POC That Worked Perfectly (Until It Didn't)
The proof of concept met (even exceeded) expectations. Fifty thousand calls over eight weeks. Containment at 74%. Average handle time cut in half. The demo to the board was crisp, the ROI model compelling, the contract signed.
Then came production.
Within 90 days of scaling to 2 million calls a month, the numbers began to move in the wrong direction. Latency climbed from 380ms to over 900ms during peak hours.
Intent accuracy - pristine in the pilot - degraded as real-world accents, background noise, and unanticipated query patterns poured in at volume.
CSAT dropped four points. Escalation rates tripled. The contact center, which had been promised relief, was firefighting two problems simultaneously: the customers the AI couldn't handle, and the internal stakeholders asking what went wrong.
Technically, nothing.
RELATED: Why Latency is the New UX in AI Conversations
The AI performed exactly as designed. The design, it turned out, had been optimized for 50,000 calls (not 2 million).
The Scale Trap: Why Pilots Don't Predict Production
The 10x Problem: How Complexity Compounds With Volume
There is an illusion in a well-run POC. Everything works. Latency is clean. Accuracy is high. The team is excited. What the POC is actually measuring, though, is your system's best-case performance like the calls it was built to handle, at a volume it was sized for, with a user base that skews toward early adopters.
The mathematics of scale are unforgiving. Edge cases that appear once in every 10,000 calls are invisible at POC volume. At 10 million calls per year, that same edge case occurs 1,000 times - enough to generate complaint clusters, regulatory flags, and operational exceptions that your team wasn't staffed to handle.
Accent variance that affects 3% of calls is negligible at 50,000 calls. At 10 million calls, it's 300,000 people facing a broken experience.
Concurrency is the infrastructure stress test that pilots rarely simulate. Running 500 concurrent calls is categorically different from running 5,000. Connection pool exhaustion, thread contention, and memory pressure at high concurrency cause latency to degrade non-linearly, where P95 response times at 5,000 concurrent calls can be 3-4x higher than at 500, even with identical underlying hardware.
Most POCs never get close to the concurrency thresholds that production routinely hits.
Top 5 architectural mistakes enterprises make moving from POC to production
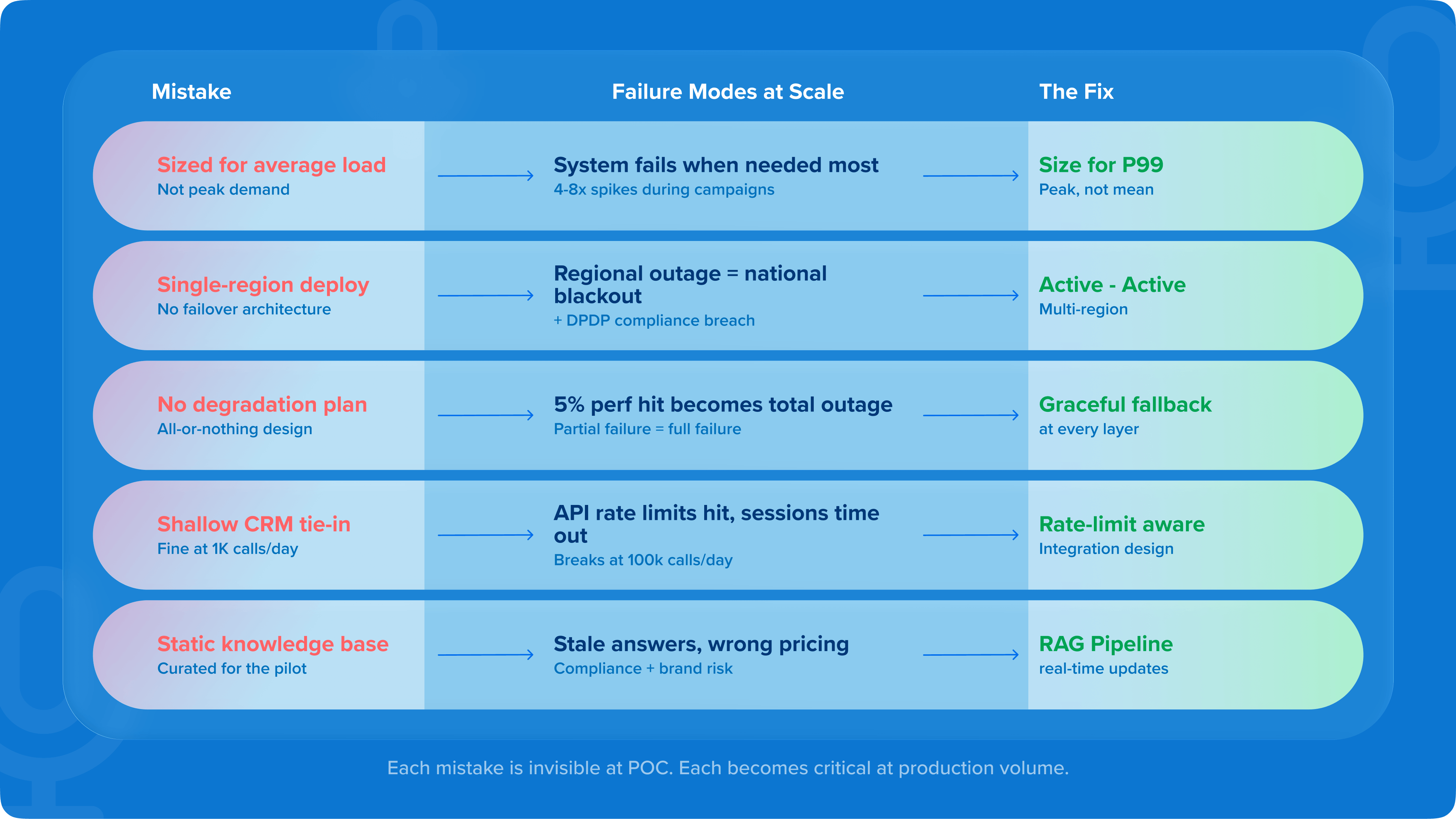
1. Designing for average load, not peak load
Enterprise contact volumes are uneven. Campaigns, billing cycles, product launches, and crisis events create spikes that can be 4-8x average volume. A system sized for average load becomes unavailable precisely when it's needed most, which during the moments of maximum customer contact.
2. Single-region deployment
The POC ran in one data center. Production needs to run across multiple. Not because of latency alone, but because data residency requirements, DPDP compliance for India, GDPR for Europe, and TCPA for the US create regulatory geography that a single-region deployment cannot satisfy. Discovering this after go-live means an architecture rebuild under production pressure.
3. No graceful degradation strategy
Most enterprise voice AI deployments either work fully or fail completely. At scale, partial failure is more common than total failure - a downstream CRM API slows, a TTS provider experiences latency, a knowledge base query times out. Systems that aren't designed to degrade gracefully instead degrade catastrophically, turning a 5% performance hit into a complete service outage.
4. Shallow CRM integration
Connecting a voice AI agent to a CRM appears straightforward at POC volume. At scale, the integration fails in ways invisible at low volume: API rate limits that the CRM vendor never mentioned until you hit them, session timeouts mid-call during high traffic, data consistency issues when records are being simultaneously updated by the AI and by human agents in the background. The integration architecture that works at 1,000 calls per day breaks at 100,000.
ALSO READ: Integrating CRM, Service Desk, and Messaging Channels with AI Service Agent
5. Knowledge bases not designed for real-time updates
In the pilot, the product catalog had 200 SKUs. In production, it has 80,000, with 300 of them changing every week. A static knowledge base built for POC is a liability in production: stale answers, outdated pricing, deprecated product references. The knowledge architecture must be designed for continuous refresh from day one.
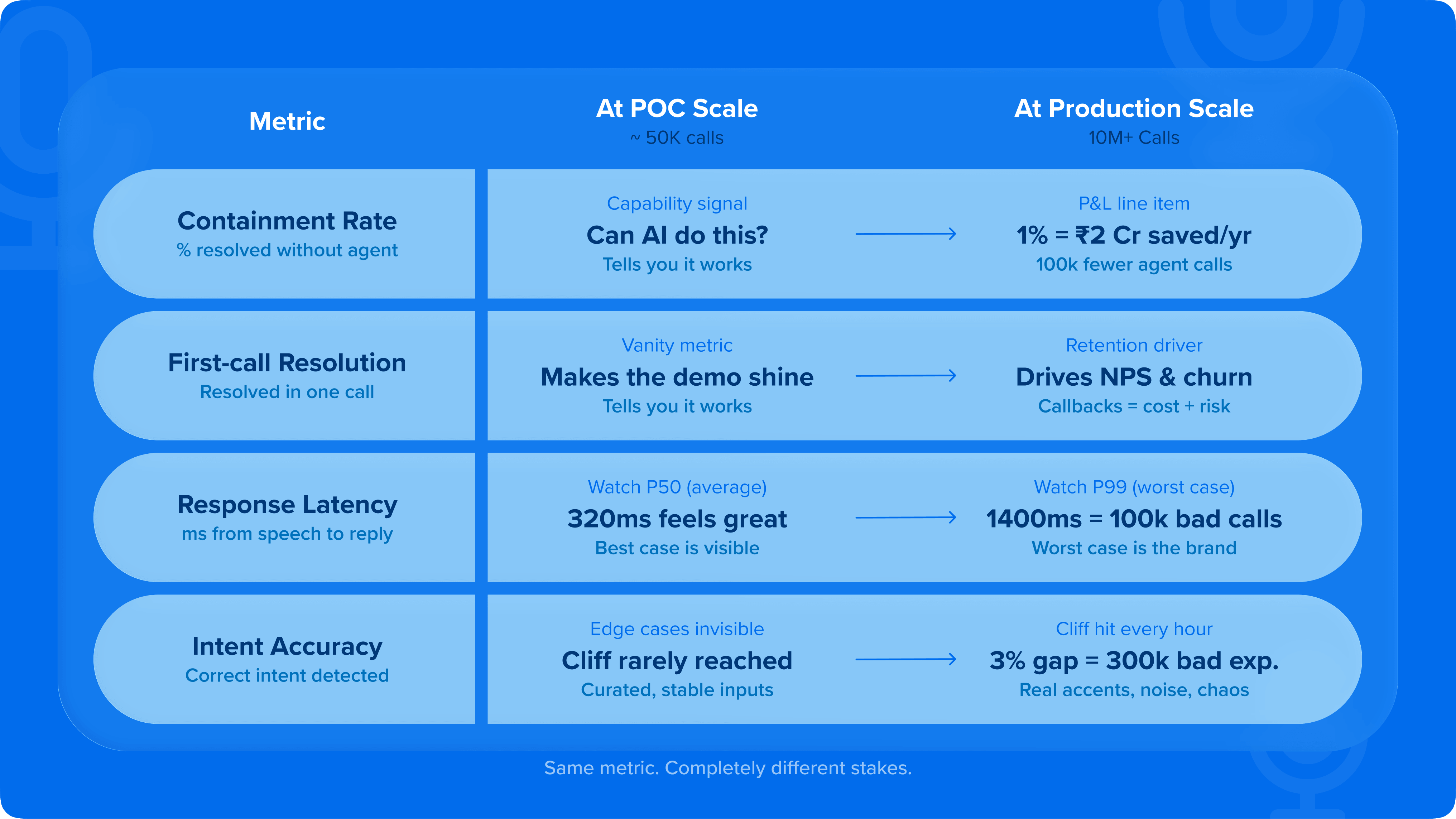
The metrics that change meaning at scale
This is the shift that catches enterprise leaders off guard: the metrics that told you the POC was working are not the same metrics deciding whether the production deployment is succeeding.
Containment rate
Containment rate at 1,000 calls is a capability signal that tells you the AI can handle the task. At 10 million calls it's a cost driver. A 1% improvement in containment at 10 million calls per year means 100,000 calls handled without human intervention. At a fully-loaded agent cost of ₹180-220 per call in India, or $8-12 in North America, that 1% is worth ₹1.8-2.2 crore annually, or more. Containment rate at scale is not an AI metric. It's a P&L line.
First-call resolution
FCR at POC scale is a vanity metric. It makes the demo look good. At production scale, it directly determines NPS and churn. Customers who resolve their issue in one call are retained. Customers who call back are expensive, and likely to leave. Every percentage point improvement in FCR at 10 million calls is a meaningful downstream revenue retention event.
Latency percentiles
When it shifts from P50 to P99, it becomes the primary concern. The average response time at POC might be 320ms - which is comfortable, almost imperceptible. But P99 latency at scale might be 1,400ms, affecting 1% of calls, which at 10 million calls means 100,000 customers experienced a pause long enough to break conversational flow. P50 is for pilots. P99 is for production.
Accuracy degradation curves
These are invisible at pilot scale. Every voice AI model has an accuracy cliff where out-of-distribution inputs, rare intents, or challenging acoustic conditions push confidence below the threshold where the AI should be attempting a response. At pilot volume, that cliff is rarely reached. At production volume, it's reached every hour.
ALSO READ: The Enterprise Guide to Voice AI Agents
Infrastructure Architecture for Enterprise-Scale Voice AI
Concurrency at scale: Designing for thousands of simultaneous calls
The concurrency question is where infrastructure decisions are irreversible. Getting it wrong means rebuilding the stack under production traffic.
The design principle is not 'how many calls do we handle today' but 'how many calls could we need to handle in the next 30 minutes, and what does our architecture do in the 15 minutes before we reach that number.'
Auto-scaling that triggers too late produces the exact latency spikes that destroy CSAT during peak events. Auto-scaling that triggers on the right leading indicators like queue depth, connection pool utilization, and intent processing time trending up prevents those spikes.
For enterprises running global operations, geographic load distribution isn't optional. A customer in Chennai and a customer in Mumbai should hit different infrastructure nodes, which is not because of compute costs, but because a regional infrastructure event shouldn't take down a national contact center operation.
ALSO READ: Voice AI for Contact Centers: The Enterprise Guide to Resolution at Scale
Multi-tenant architecture: Managing multiple business units without interference
The large enterprise deploying voice AI deploys many systems across business units, geographies, product lines, and campaign types on shared infrastructure. The blast radius problem is real: when the insurance renewal campaign spikes to 10x its normal volume during a claims event, does it degrade the wealth management service line running on the same infrastructure?
Efficient multi-tenant architecture prevents this through resource isolation at the namespace level, capacity reservations per tenant that guarantee floor-level performance even under shared-infrastructure stress, and burst limits that prevent any single tenant from consuming the headroom reserved for others.
The governance layer matters as much as the technical layer. Enterprises need clear policies for what happens when a business unit exceeds its reserved capacity:
- Does it queue?
- Does it scale into shared headroom?
- Does it auto-escalate to human agents?
Getting this wrong produces internal conflict that derails enterprise AI programmes faster than any technical failure.
Disaster recovery, failover, and what 99.99% uptime means
99.99% uptime is 52 minutes of downtime per year. It sounds negligible. For a contact center that handles 100,000 calls per day, 52 minutes of downtime during peak hours means roughly 6,000-8,000 unanswered or failed calls. At enterprise-scale, every percentage point of availability has a monetary and reputational value that needs to be calculated before signing the SLA.
Active-active architecture, where traffic is distributed across two live environments simultaneously, provides the fastest failover - typically under 30 seconds - because no warm-up is required.
Active-passive architecture, where the secondary environment is ready but not serving traffic, costs less but requires 2-5 minutes for promotion to active. For enterprises where every minute of downtime has a quantifiable cost, active-active is the right answer. For enterprises where cost optimization is the primary constraint, active-passive with aggressive RTO targets may be adequate.
Geographic failover adds another layer of resilience, plus another layer of data residency complexity. If your primary infrastructure is in Mumbai and your failover is in Singapore, what are the data transfer implications under DPDP? These questions need answers in architecture design.
Data Architecture and Knowledge Management at Scale
Keeping AI accurate across 80,000 SKUs, changing policies, and Live workflows
The knowledge management problem is one that enterprise teams systematically underestimate. In the pilot, knowledge is a controlled variable containing a curated set of FAQs, stable product information, and a handful of workflows. In production,
knowledge is a living organism. Product catalogues change weekly. Policy terms are updated overnight. Regulatory requirements shift. Promotions go live and expire. And the AI, if its knowledge base doesn't keep pace, starts giving wrong answers to customers.
At scale, wrong answers are a compliance risk, a brand risk, and a churn risk. Telling a customer the wrong premium amount, or describing a policy condition that no longer applies, has consequences that go well beyond a low CSAT score.
Retrieval-augmented generation (RAG) pipelines solve the retraining problem by separating the AI's language understanding, which is stable, from its factual knowledge - which changes.
When a policy term updates, the knowledge base updates. The AI doesn't need to be retrained; it retrieves the new information at inference time. At 80,000 SKUs with weekly updates, this is the only architecture that works.
Conversation data storage, PII governance, and compliance at volume
At 10 million calls, PII handling is an operational architecture decision that touches storage design, retention policy, access control, audit trails, and the ability to respond to a data principal's rights request within regulatory timelines.
DPDP in India, GDPR across the EU, and TCPA in the US create a patchwork of requirements that intersect badly when your voice AI operates across markets.
The practical architecture question isn't 'are we compliant with each regulation individually' but 'can we respond to a data deletion request from an EU customer while simultaneously generating an audit trail for an Indian regulatory inquiry, without those two operations interfering with each other.'
Call recording consent at 10 million calls is an automated workflow involving opt-in capture at the start of each call, consent state stored against the session and the customer record, withdrawal handling that triggers automated deletion pipelines, and retention schedules that enforce expiry without manual intervention. Building this correctly from the start is significantly cheaper than retrofitting it under regulatory pressure.
Feedback loops and continuous model improvement in production
The compounding advantage of scale is the training signal. An enterprise that has processed 10 million calls with their voice AI has a dataset of customer intents, language patterns, resolution paths, and failure modes that no new entrant can replicate. This is proprietary data. If it's being captured and operationalized correctly, it should make the system meaningfully better every quarter.
The operational challenge is continuous improvement without production disruption. Shadow deployment - which is about running a new model version against live traffic in read-only mode, without serving its outputs to customers - allows model evaluation at production scale without risk.
A/B testing conversation flows with statistical rigour identifies improvements with confidence before full rollout. Progressive rollout of model updates, starting with 1-5% of traffic and scaling on quality signals, prevents a bad model update from degrading the experience of 10 million callers simultaneously.
The enterprises that treat voice AI as a deployed product will fall behind those that treat it as a continuously improving system. At scale, the compounding effect of incremental improvement is large. A 0.5% monthly improvement in containment rate, sustained over two years, produces a radically different cost structure than a system that performs at go-live levels indefinitely.
Security and Compliance at Enterprise-Scale
Authentication, anti-spoofing, and voice biometrics at high volume
The voice channel has a security surface that text channels don't: it is intrinsically personal, easily impersonated by determined bad actors, and operates without the visual verification cues that in-person or video interactions provide. At scale, this creates fraud exposure that grows with volume.
Voice biometrics - passive authentication based on the acoustic properties of a caller's voice - solves two problems simultaneously. It removes the friction of security questions (no more 'what is your mother's maiden name') while providing continuous authentication throughout the call, not just at the point of entry.
For BFSI deployments, where a caller impersonating an account holder can cause direct financial harm, the false acceptance rate requirement is typically below 0.5% - meaning the system incorrectly authenticates an impersonator less than 1 in 200 attempts.
At high volume, the engineering requirement is that biometric processing doesn't add latency to the conversation flow. Authentication should complete in the background during the first 3-5 seconds of natural conversation.
Regulatory compliance across geographies: GDPR, DPDP, TCPA, and the patchwork problem
The global enterprise faces a compliance architecture choice with significant long-term cost implications: build once for the most restrictive regulatory market and apply globally, or build market-specific configurations that satisfy each jurisdiction's requirements separately.
The first approach is simpler to operate and audit. The cost is over-compliance in less restrictive markets. The second approach is more complex to build and more expensive to maintain, but allows the business to maximise data utility in each jurisdiction. The risk is that a configuration error in one market creates compliance exposure precisely where you thought you were covered.
Call recording, consent, and what changes at 10 million calls
At POC scale, consent management is often handled manually - a notice read at the start of each call, logged in a spreadsheet, reviewed periodically. At 10 million calls, that model is untenable. Consent becomes an automated workflow: capture, log, propagate, and enforce.
The architecture must handle consent withdrawal retroactively, when a customer withdraws consent after 18 months of calls, what happens to the 140 recorded conversations in your system?
The answer must be an automated deletion pipeline that executes within the regulatory deadline, produces an audit log of what was deleted, and doesn't require human intervention at scale.
Operational Excellence: Running Voice AI as Enterprise Infrastructure
Monitoring, observability, and catching quality degradation before it hits CSAT
The operational difference between enterprises that run voice AI well at scale and those that don't comes down to one thing: whether their observability infrastructure tells them what's about to happen, or only what already happened.
A dashboard that shows yesterday's CSAT is a post-mortem tool. The operations center that catches quality degradation before customers feel it is watching a different set of signals: P95 latency trends over the last 15 minutes, intent confidence score
distribution shifting toward the lower end (an early indicator of accuracy degradation), escalation rate by intent cluster rising in specific categories (indicating knowledge base staleness or an upstream system issue), and silence rate on text-to-speech output increasing (often the first signal of a TTS provider latency event).
Human-in-the-Loop: Designing escalation that doesn't break the experience
Escalation to a human agent is not a failure state. It's a feature, if designed correctly.
What breaks at scale:
- Cold transfers that reset context
- Forcing the customer to repeat everything they told the AI
- Handoff queues longer than the AI resolution path, creating a situation where escalation worsens the experience
- Human agents who receive the call without knowing what the AI already tried, what information was collected, or why the escalation was triggered
RELATED: What is Human in the Loop? A Primer for Enterprise Leaders
The design principle for escalation is that the human agent should know more when they pick up the call than the customer does. They should have: the full conversation transcript, the intent that triggered escalation, the attempted resolution path, the customer's sentiment signal, and relevant account information pre-loaded. The first thing the agent says should not be 'how can I help you today' but that the context has carried across.
Change management: The Internal Playbook for Enterprise-Wide Rollout
Voice AI deployments fail more often because of internal resistance than technology failure. This is underappreciated in technology evaluations and critical to success.
The frontline contact center agent who has been told that AI will 'handle routine calls' hears something specific: their job is at risk.
If the deployment leadership doesn't address this directly, they get passive resistance at best and active sabotage at worst - agents who route calls around the AI, who frame escalation in ways that inflate AI failure rates, who become the most vocal critics of a technology they were never invited to champion.
The playbook for successful change management has four elements:
- First, stakeholder alignment before go-live, not only the CTO and CCO, but team leads and floor supervisors who will shape how the AI is received day-to-day.
- Second, agent retraining is framed specifically as augmentation: 'you will spend less time on routine queries and more time on the conversations that actually require your judgment.'
- Third, early wins that are visible to frontline staff.
- Fourth, KPIs that prove to frontline managers that containment and AI resolution rates help their team, not threaten it.
How Haptik Approaches Enterprise Voice AI at Scale
What 500+ enterprise deployments teaches you
There is a category of knowledge that cannot be written in a product specification or learned in a lab. It comes from watching what breaks in production at scale, across industries, across languages, across contact center cultures. After 500+ enterprise deployments, Haptik's institutional knowledge about failure modes that pilots never surface is a genuine differentiator.
Forward-deployed engineering
The model of deploying an enterprise platform and handing it over to the client's internal team assumes that the client has the capability to run what was just built.
At voice AI scale, that assumption is usually wrong - not because enterprise IT teams are incapable, but because the operational knowledge required to optimize a live voice AI deployment at 10 million calls is genuinely specialist and genuinely rare.
Haptik's forward-deployed engineering model means engineers remain embedded with enterprise teams through the scale curve. Model updates under live traffic, escalation design based on real call data, knowledge base governance as product catalogues evolve require a partner who is in the room.
The outcomes that define scale success
The metrics that matter at scale are business metrics.
A 40% reduction in call handling time sounds like a contact center efficiency number. At 10 million calls per year, it's a cost per resolution transformation.
CSAT maintenance as volume triples is a proof point that the design choices made at 50,000 calls hold under real load.
Containment rate improvement from 68% to 79% over 18 months of production operation is the compounding return on continuous improvement investment.
These are the numbers that get presented in the boardroom. The enterprises that reach them are the ones that designed for scale before they needed it.
The Enterprise Buyer's Framework for Scale Evaluation
Scalability claims vs proof: What to ask the vendors
Every enterprise voice AI vendor claims to scale. The question is whether that claim comes with evidence or with confidence.
RELATED: How to Choose the Best Voice AI Platform for Enterprise CX
The questions that separate genuine scale capability from well-packaged aspiration:
The Bottom Line: Design for Scale on Day One
The boardroom conversation about voice AI in 2026 is about whether the deployment is built to last. Enterprises that design their voice AI infrastructure for the volume they intend to reach avoid the most expensive failure mode in the space: the successful pilot that collapses in production.
Haptik has seen this transition play out at hundreds of enterprise deployments, and the differentiating factor is consistent: the winners treated architecture as a strategic decision, not a technical detail to resolve later.
Design for scale on day one. The cost of rebuilding at scale is not just financial but also the cost of losing the boardroom's confidence in a technology that, correctly deployed, transforms what enterprise CX can be.
FAQs





source on Google