

Enterprise IT leaders treat Voice AI deployment like a traditional software integration. They assume a couple of webhook connections and a standard CRM sync are enough to get an agent live. This assumption is a fast track to failed production deployments.
Unlike traditional AI, an enterprise voice AI agent lives and dies in the live media stream. It must interact with legacy telephony, manage database timeouts mid-sentence, preserve context across human handoffs, and protect sensitive data at the edge.
As we navigate the production landscapes of 2026, the gap between a successful proof of concept and an industrialized deployment comes down to systems engineering.
This blog outlines the concrete architectural steps required to embed an agentic voice layer into your existing enterprise infrastructure without accumulating crippling technical debt.
Telephony Integration: Connecting the AI Agent to the Live Media Stream
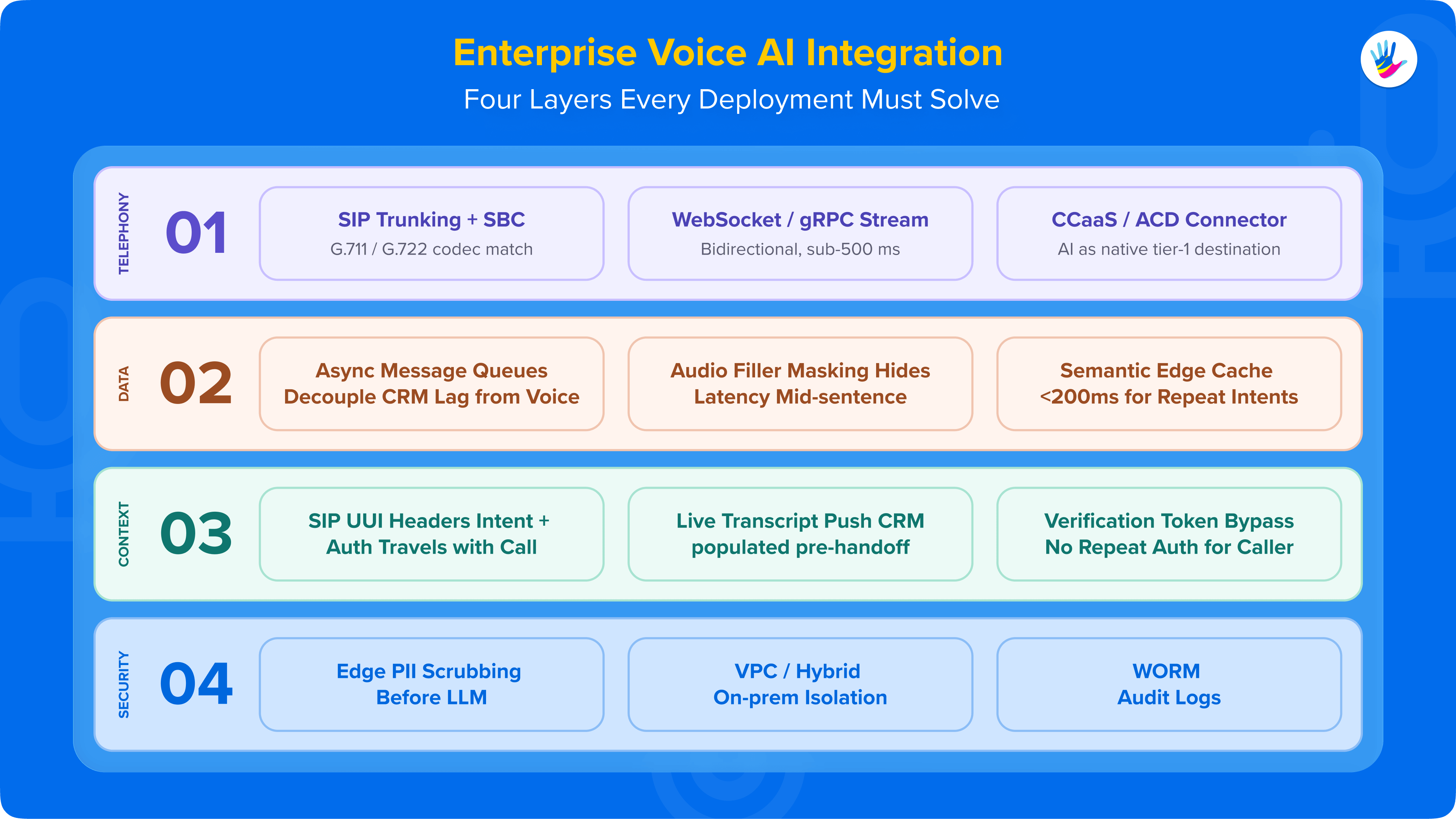
The first integration hurdle is getting the audio signal from the public phone network into your AI orchestration layer without introducing devastating latency.
If your connection pipeline takes more than 500ms to process raw audio, your conversational fluidity will fall apart completely.
ALSO READ: Why Latency Is the New UX in Voice AI
Configuring SIP trunking and Session Border Controllers (SBCs)
Enterprise deployment requires establishing secure Session Initiation Protocol (SIP) connections between your carrier network and the AI orchestration gateway.
Session Border Controllers must be configured to act as the primary traffic cops, securely managing the boundary between your internal network and the public cloud.
IT teams must establish explicit network routing rules to fork or terminate audio streams at the gateway level. Proper audio codec matching, specifically prioritizing low-bandwidth options like G.711 or high-definition G.722, is non-negotiable to prevent acoustic distortion before the signal even reaches the speech-to-text engine.
Orchestrating real-time audio streams via WebSockets and gRPC
Traditional HTTP polling cannot sustain live phone conversations because it introduces asynchronous delays. Production architectures utilize continuous, bidirectional streams powered by WebSockets or gRPC pipelines.
ALSO READ: Voice AI for Contact Centers: The Enterprise Guide to Resolution at Scale
By leveraging gRPC, systems can stream chunked tokens of synthesized text-to-speech audio back to the caller while simultaneously processing inbound speech. Architects must also configure aggressive Packet Loss Concealment (PLC) algorithms at the gateway to maintain voice recognition accuracy over unstable mobile connections.
Splicing into existing CCaaS and on-prem contact center stacks
Modern deployment requires building native connectors directly into legacy systems. The AI agent must plug into these platforms as a core telephony destination that behaves like a human tier-1 agent.
This requires mapping out clear dial-plan routing rules within your Automatic Call Distributor (ACD). The system must be engineered to let the Voice AI intercept 100% of standard inbound volumes, handling containment or qualification before the call ever touches a human queue.
RELATED: Voice AI For Lead Qualification: How Enterprises Are Calling Every Lead In 5 Minutes
Data Layer Orchestration: Solving the Legacy API Timeout Dilemma
An autonomous agent needs real-time read and write access to your underlying enterprise databases to resolve customer queries.
However, if your legacy enterprise resource planning (ERP) or customer relationship management (CRM) database takes three seconds to return a payload, the caller will assume the line is dead and hang up.
ALSO READ: Data Privacy in Voice AI: The Enterprise Compliance Guide
Implementing asynchronous read/write workflows for slow databases
To prevent database lags from stalling a live conversation, architects must decouple the conversational reasoning loop from transactional back-end queries. The voice engine should run on an independent thread, utilizing event-driven message queues to update records asynchronously.
When an agent triggers a slow operational task, such as processing a financial refund or updating a shipping manifest, the transaction is pushed to the queue. The conversation continues uninterrupted while background workers execute the database change, pulling status updates without freezing the user experience.
Conversational masking: Managing database latency with audio fillers
When a data lookup is unavoidable before the next conversational step, the AI must explicitly mask the backend latency. The system should be programmed to dynamically deploy context-aware verbal fillers like "Let me pull up your account statement for you..." or "I am fetching those details right now."
ALSO READ: How Latency and Interruption Handling Define Voice AI Quality
These audio fillers must be programmatically synced with backend API status codes. If the system receives a 202 Accepted or an ongoing pending status, it triggers secondary, natural acoustic anchors to keep the customer engaged while the infrastructure finishes processing.
Strategic semantic caching for high-frequency transactions
Hitting core enterprise databases for every repetitive query creates unsustainable computational overhead and system strain. Enterprise architectures implement semantic caching layers at the network edge to evaluate incoming statements based on contextual meaning rather than exact string matching.
If a caller asks "Where is my package?" and another asks "Can you track my delivery?", the semantic cache recognizes the identical underlying intent.
RELATED: Voice AI Use Cases for Customer Support That Actually Move the Needle
It instantly pulls the structural response template from the edge cache, bypassing the core database entirely and dropping transaction response latency to under 200ms.
State Management and Context Preservation During Human Handoffs
The moment an AI agent encounters a complex edge case and must transfer a frustrated caller to a human representative, the customer journey faces its highest point of friction. If the human agent picks up the line and asks the customer to repeat their problem from scratch, your integration has failed.
Passing contextual metadata via SIP User-to-User Information (UUI) headers
To ensure continuity, conversational state data must travel alongside the physical voice routing packet. Architects accomplish this by encoding the customer's authenticated status, intent classification, and verification tokens directly into the SIP User-to-User Information (UUI) headers.
ALSO READ: Scaling Voice AI for Enterprises: What Changes After 10 Million Calls
As the call is routed through downstream Automatic Call Distribution (ACD) nodes, these metadata headers must remain intact. This allows the receiving platform to identify exactly where the caller dropped off in the automated workflow without dropping the media stream.
Injecting real-time conversational transcripts into the agent desktop CRM
As the voice agent handles the call, the speech-to-text transcripts must stream concurrently into a centralized data pipeline. The moment an escalation handoff is triggered, this data payload must be pushed directly into the human agent’s desktop console workspace.
The system should combine the raw transcript with a concise, AI-generated summary field. This allows a human customer service representative to digest a complex, multi-minute automated interaction within two seconds of picking up the handset.
Intent mapping to bypass redundant interactive authentication
If a customer has already passed identity verification protocols while speaking to the Voice AI, that authenticated status must be preserved across the enterprise stack. The system architecture should generate a secure, temporary verification token that maps directly to the active session ID.
When the call lands on a human agent's console, this token triggers a bypassed security state. This prevents the downstream telephony logic from forcing the user back into a redundant interactive voice response (IVR) verification loop, preserving average handle time.
Edge Security and Compliance: Architectural Guardrails for Data Privacy
When voice agents process sensitive data like credit card numbers, national identification records, or health history, security cannot be managed casually in post-processing. With regulations like the DPDP Act strictly enforced, compliance must be woven directly into your runtime architecture.
Real-time PII and PCI-DSS scrubbing at the ingestion gateway
Data minimization requires that Personally Identifiable Information (PII) be stripped out at the absolute edge of your ingestion architecture. Security models must sit directly between your speech-to-text transcriber and the core large language model (LLM) orchestration engine.
These edge guardrails screen incoming audio and text, automatically masking sensitive strings before they hit transaction logs or third-party reasoning APIs. This ensures your data stores contain only anonymized tokens, mitigating the systemic blast radius of potential data leaks.
Private cloud isolation vs hybrid on-prem architectures
Large enterprises cannot risk exposing proprietary customer data or operational logic to public, multi-tenant cloud models. The voice integration architecture must utilize isolated Virtual Private Clouds (VPCs) or hybrid on-prem server topologies.
By deploying self-hosted or dedicated model instances with secure private endpoints, your network traffic remains entirely contained within corporate boundaries. This layout ensures your proprietary conversational data cannot be utilized by external vendors for public model training.
Immutable decision logging and auditable system trails
To satisfy regulatory audits, every action executed by an autonomous voice agent must possess a deterministic, unalterable record. System architects must implement immutable write-once-read-many (WORM) logging pipelines for every step of the AI's decision-making logic.
These logs must clearly separate abstract business logic pathways from actual personal customer data transcripts. This dual-track logging strategy allows legal and compliance teams to verify algorithmic safety protocols without compromising individual user privacy rights.
Testing and Day 2 Performance Monitoring: Sandboxes to Production
A voice integration that performs flawlessly in a quiet staging environment can quickly break down under the chaos of unpredictable real-world phone line inputs.
Automated load testing for concurrent audio streams
Before opening production channels, IT teams must simulate the realities of high-volume operations. This requires utilizing automated testing engines to generate thousands of simultaneous, synthetic SIP calls directly into the integration gateway.
ALSO READ: How to Choose the Best Voice AI Platform for Enterprise CX
Engineers must monitor core infrastructure bottlenecks, tracking how token-streaming latency scales under maximum concurrency spikes. This performance profile establishes the baseline thresholds required to trigger graceful system fallbacks before compute limits are breached.
Fine-tuning phonetic edge cases and acoustic deviations
Speech recognition components must be robust enough to decode low-quality microphone inputs, heavy ambient background noise, and varying regional accents. System integration must include the deployment of custom phonetic dictionaries directly into the speech-to-text pipeline.
These specialized dictionaries map specific company SKU numbers, legal terms, and brand names to the engine's core vocabulary. Continuous regression testing against real-world call recordings ensures accuracy rates remain stable across diverse demographic groups.
Canary deployments and shadow routing strategies
Deploying an enterprise voice agent is never an all-or-nothing event. A resilient rollout architecture uses canary deployments, routing a minor slice which is typically 2% to 5% of live production traffic to the AI agent while keeping the remaining volume on legacy paths.
Alternatively, running the system in "shadow mode" routes the audio of a live human call to the AI agent in parallel. This allows teams to evaluate the voice bot's real-time intent matching and data query generation against actual human performance without impacting the live caller experience.
The Bottom Line
Transitioning an autonomous voice agent from a pilot project to an industrialized enterprise asset is fundamentally a systems engineering challenge, not a conversational script task. Success requires solving for low-latency bidirectional media streams, decoupling slow backend databases via asynchronous queues, and maintaining absolute context across legacy telephony handoffs. By approaching your deployment with an infrastructure-first methodology, you build a resilient voice engine capable of driving measurable operational resolution at scale.





source on Google