

Language capabilities have always been very critical at Haptik. We believe that for Conversational AI to be truly successful, it should be able to interact with users in the language they are most comfortable with.
Furthermore, supporting vernacular languages becomes a non-negotiable as we expand our global client base to regions where English is not the primary language of communication. In order to ensure world-class multilingual capabilities, we took a leap forward from treating it as a checkbox capability and tried multiple approaches.
The Initial approach and its Challenges
At first, we built out native language models for different languages and were fairly successful. We were able to build accurate language models for multiple Indian languages like Hindi, Gujrati, Marathi etc. It was validated when the Govt of Maharashtra, partnered with Haptik to launch the Aaple Sarkar bot in multiple languages like Hindi and Marathi.
While we worked on multilingual native models, our Machine Learning team parallely worked on improving our English models by using fundamentally different approaches to deliver better accuracy than other alternatives in the market. A true testament to this effort was the recent recognition by EMNLP where they compared the performance of Haptik’s NLP to other popular vendors and Haptik beat others.

One of the bigger challenges for us was to make sure that all our language models benefit from these improvements and maintain a similar level of accuracy. Additionally, our other modules like Smart Assist, Disambiguation and Smart Variants contributing to our English conversational capabilities had to be replicated. This meant duplication of models for each and every language we wanted to support and scale it further. To fill in these gaps, we started considering translation.
Using Translation and its Challenges
Our approach of Translation helps in making sure that all improvements in the English model are also available for other languages.
The way we initially envisioned it to work is illustrated below. Essentially, the translation service sits between the user and our ML pipeline and translates all the incoming and outgoing messages.

This has two advantages -
a) The underlying English model powers all languages and automatically leverages improvements
b) Easily start supporting additional languages as and when required
There are many companies in the market today who follow this approach to provide multilingual support. However, when we dug a little deeper into this solution we noticed that using translation had its own challenges.
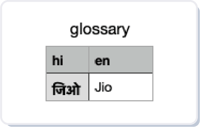
• Domain Specialization - One disadvantage of using a translation service is that it won’t work on domain-specific terms and might incorrectly translate them.
Eg: Jio typed in Hindi (जिओ) would translate to its literal translation “live” instead of being treated as a brand name.
• Numbers - Another challenge is that traditional translation services were very bad in translating numbers.
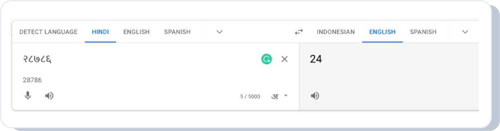
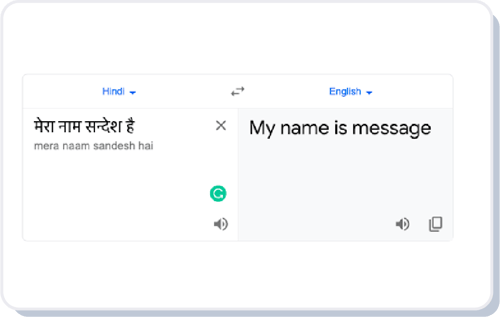
1. Person Names - The third challenge was to recognize proper nouns like person names without having them go through literal translations.
An example of this is the name Sandesh (सन्देश), which literally translates to “Message”. So if a user sent a message as “मेरा नाम सन्देश है” (my name is sandesh), it would get translated to “My name is message” instead.
2. Cultural Nuances - The final challenge was that translation often loses cultural nuances and colloquialisms. This made us realize that we could not use a translation service to translate and send the bot responses.
We realized very quickly that just using translation will not work and we needed to find a more advanced way which will solve the above challenges.
Read on: Multilingual Chatbot: Driving Customer Engagement Globally
Introducing Linguist Pro
A new approach leveraging advanced custom translation modules on top of the translation layer.
These advanced modules act like a correction layer that can be configured to correct wrong translations, capture names accurately and make translation more domain-specific. However, the bigger benefit is that since this still works on top of our base English language model, it is able to leverage all the existing and upcoming benefits available.
Here’s how we tackled each of the challenges:
1. Domain Specialization - For domain specialization, we use a module called glossary that lets you define a custom translation pair of the original word and translated word. This way we can customize the translation for different domains.
2. Numbers - For numbers, we built our own custom translation module that translates numbers with 100% accuracy unlike the translation services available off the shelf.
a) Off-the-shelf translation service
b) Haptik’s custom translator

3. Person Names - For capturing proper nouns like person names correctly we built a custom entity extractor that is able to capture the names without considering the literal translations of these names.
4. Cultural Nuances - For managing cultural nuances and colloquialisms better in bot response we realized that the best way to do this is to make it fully configurable so that the person building the IVA has full control on defining the bot responses to make sure the responses can be customized based on how the business wants to communicate with its users.
.png?width=500&name=Asset%201%20(1).png)
Architecturally, this is how the Linguist Pro package works
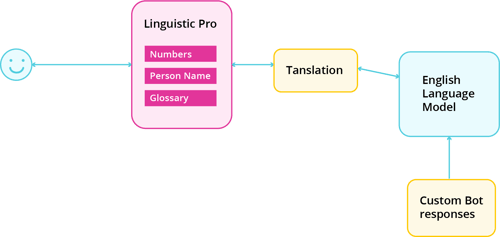
As previously mentioned apart from solving these issues now our multilingual IVAs get to take advantage of all the capabilities like Smart Assist, Disambiguation and Smart Variants out of the box.

There are some companies that use native models and some that use a pure translation based approach. Haptik is the only company that is leveraging a truly hybrid approach to bring the best of both worlds.
Overall this is how the different offerings stack up against each other
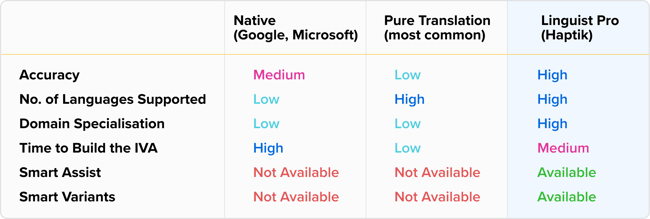
Based on the above table we can confidently say that Linguist Pro is the best approach to powering multilingual IVAs and we have already seen a lot of our clients reap the benefits of this approach.
Want to develop an Intelligent Virtual Assistant solution for your brand?



-png.png?width=352&name=Ikhophi%20ye-Bots%20Going%20Live%20-%20LinkedIn%20(1)-png.png)

source on Google