
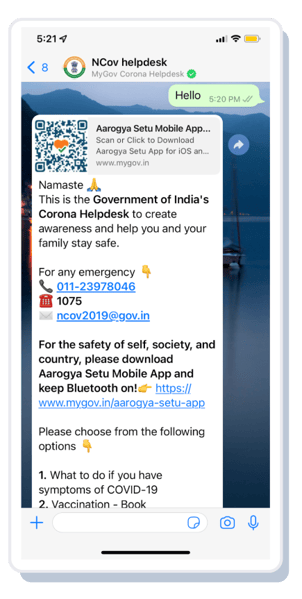
With vaccination drives running in full swing across the country, the cloud of pessimism and negativity brought by COVID 19 is slowly subsiding. Though with the emergence of new variants, we are still far from saying that the battle is over, but we are better prepared now.
It gives us immense pride that we are playing a role in helping the nation fight this crisis through our MyGov Corona Helpdesk – the official Government of India WhatsApp chatbot. It all started in March 2020 with a simple goal to ensure that people had access to accurate and reliable information about the virus. With this aim in mind, and given the accessibility of WhatsApp as a medium and people's preference to chat, we developed a chatbot within five days to help answer queries of 70 million+ users and 250 million+ conversations to tackle the spread of misinformation. Today the chatbot is equipped to facilitate the hassle-free booking of vaccination appointments and downloading of certificates.
Building the World's Largest Chatbot is a mammoth task. Our team showed incredible persistence and effort to develop an optimal solution between all the chaos and challenges. Here are a few of our key learnings that helped us while implementing an IVA solution of this scale :
The WhatsApp Enterprise Client Infra
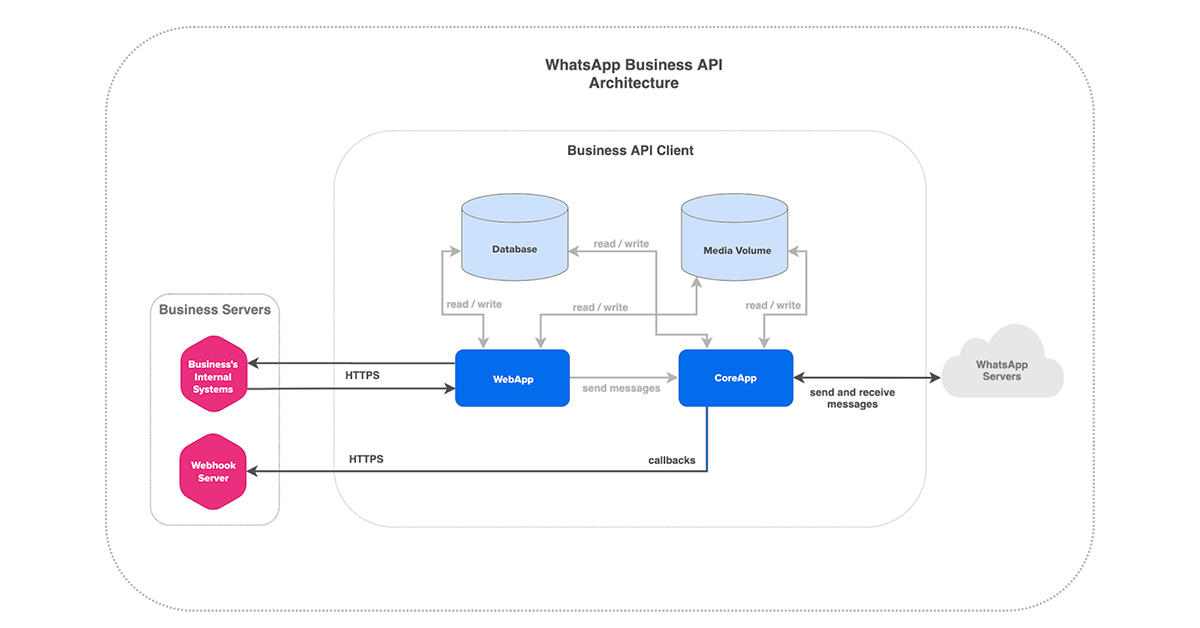
https://developers.facebook.com/docs/whatsapp/on-premises/get-started/client-architecture
Below is what helps us as a BSP. To enable the end-users to communicate with the business. And this is something that requires detailed understanding so that one can deploy these at scale. Few optimizations mentioned in this blog are based on optimizing this system.
Message size & number of responses impact scale
So we wondered how to keep the load on our systems along with the WhatsApp system. Do we break a response message into multiple messages or send one long message? After a lot of analysis, we stuck to the latter.
So the key is, if you are sending out responses to users on WhatsApp, send one long message rather than five short messages as that puts less load on the WhatsApp system. You might want to respond with two messages for some UX reasons, but that should be the maximum.
Reason:
- Reduces the number of API calls we make to WhatsApp business API clients.
- Reduces the network usage
- Impacts the "WhatsApp limits and Message Inbound & Outbound rate" issues mentioned in the next section
Understanding WhatsApp message inbound & outbound rate
WhatsApp core apps have certain limitations when handling inbound messages from the user's end and responses from the Haptik / Bot side.
To understand this better, if we have 32 shards systems, then for simple plain text messaging, we could be doing 250 TPS inbound from the user and 250 TPS outbound to the user, which accounts for 500 TPS.
Suppose we send too many outbound messages, which will eat up the total TPS and might lead to the slowness of inbound messages.
To track this, we created a dashboard to monitor this and made sure we added a very small delay for outbound if inbound was very high.
The idea is to make sure you're tracking both of them and not blindly sending out responses.
-png.png)
Disabling read receipts shown to end-user
When one enables read receipts on the Webhook URL of WhatsApp Business Enterprise Client, that implies when an inbound message from WhatsApp users hits us, we hit WhatsApp client with 2 API calls.
- The blue tick read receipt via V1/message APIs
- The response message via V1/message API
So for 1 million inbound messages, we hit the container 2 million times, which can put a huge unnecessary load on the WA system.
Here we need to take an informed call. If it's a very high volume number, remove read receipts (blue tick); else, let it be enabled.
Here is the WhatsApp documentation for this: https://developers.facebook.com/docs/whatsapp/guides/mark-as-read/
Media sending using URL impacts WhatsApp containers and load on core apps
There is an additional load on the WhatsApp system when using Media URL compared to Media ID. The best and optimized way to send media in response to users is by using media_id and referencing the v1 messages API. Upload once to Biz API and upload one to WA Infra. No matter how often you send. Media URL is always fetched (Biz API doesn't know if the image is the same (URL could generate dynamic image)). Once fetched, if the image is identical, it won't be uploaded to WA Infra again, but it will be fetched every time from the link, which is expensive.
A text message like: This is an image for your order. https://imagelocation.com/img1.png puts more load on the system.
An ML pipeline that can handle 1000s of TPS of user queries
To be able to understand what anyone in India is trying to say, we needed to have an ML pipeline in place that should
- Quickly understand user queries and respond back
- Handle English and Hindi languages
- Handle spelling mistakes
- Scale per traffic
And we had the right blend of everything to power our Intelligent Virtual Assistant.
The infra supporting this initiative is huge, and here I will try to give you a gist of all the components. Sadly, I won't be able to deep dive into each of them, but I promise to come back with a detailed blog on the topic.
You can still check out the TechStack: https://stackshare.io/haptik/haptik
Keep checking the Haptik blog as we will be back with a detailed blog on system design and how this entire WhatsApp platform works.
Simple flows & UX are impactful
When serving the people of the whole country, the flow of a chatbot needs to be very simple. People are coming to chat specifically about COVID-19, and it's our responsibility to give them an excellent UX so that their queries get resolved quickly and with minimum effort. Some pointers to consider:
Menu
Have a simple menu for users to pick the right intent, which the bot can support end-to-end. We went with a long main Menu so that the user does not have to go under the nested menu to find a solution.
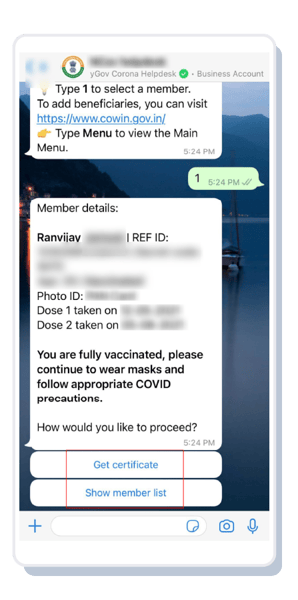
Let's see an example of a flow for the use-case "Book Appointment":
A user can start booking their appointment by just sending a straightforward message. In the background, we have used our serverless code editor to make API calls to CoWin at scale. (We will discuss it further in the next blog)

Usage of List, message, and buttons
Make it easy for the user; they don't have to type much; they can click from the options presented.
Recently, when the download certificate feature was launched, Mr. Shashi Tharoor & Mr. Adani tweeted about this. This brought an immense load to the system usage went to 3x.
A data lake and analytics that scale on the go
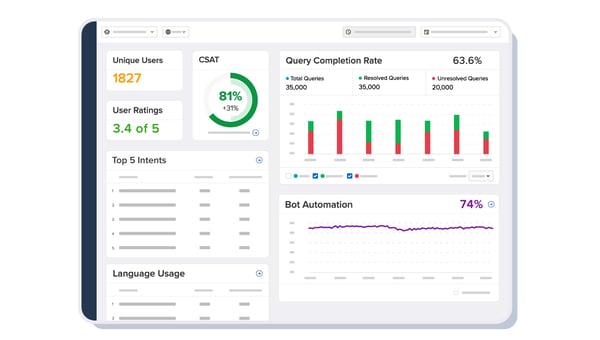
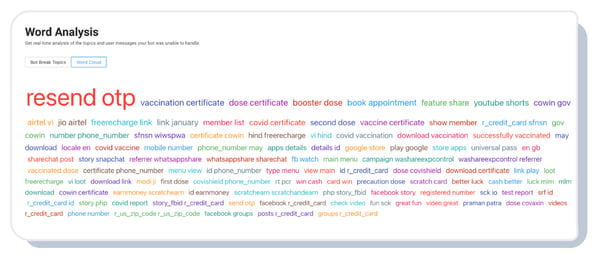
Running a bot at this scale requires great analytics to ensure the users get the most out of this solution. Being a PAN India solution where everyone has a different way to ask questions, it is essential to check if the bot understands the user query and gives the best possible answer.
- One cannot control users to follow the desired flow during any conversation
- Users might type anything in free form, which can be outside the context of the bot
- Users might be interpreting a bot response in a different way than intended
- Users might be looking for more information than presented
Our Analytics built with top-notch metrics generated on AI-driven technology helped us fulfill all the above prerequisites. Our AI recommendations helped us understand the users' tone, sentiment, and much more.
Coming in Part 2
- Detailed design of the system and components to run a chatbot at such scale
- How does our ML pipeline work and learns on its own





source on Google